Autoscaling Now In Public Preview: Build, Run, and Autoscale Apps Globally
Today marks a monumental milestone: Autoscaling is now in public preview and available to all our users.
Don't like to wake up in the middle of the night to scale up? Do you still have nightmares of the time you forgot to scale down your cloud infrastructure? Autoscaling is the answer: we adjust infrastructure to demand dynamically.
We built our autoscaling feature to be:
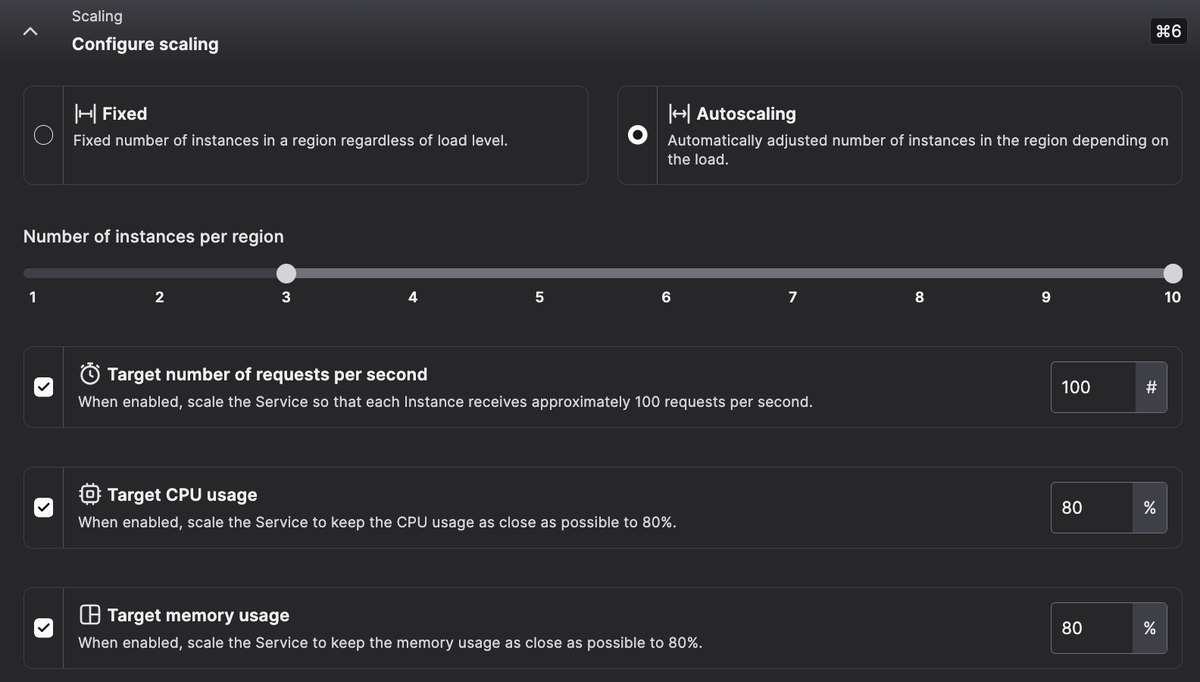
- Flexible: you define policies based on three critical metrics: requests per second, CPU usage, and memory consumption. You can fine-tune autoscaling triggers using a combination of these criteria or start with our default settings.
- Controllable: You're in full control of the cost with a simple slider defining the maximum number of instances we will spawn on your behalf. We log all up- and down-scaling operations so that you can track everything that was done.
- Global: autoscaling applies across all regions you deployed to, but we don't stop there. For global deployments, you have the power to tailor scaling policies region by region, ensuring optimal performance and cost-efficiency wherever your application runs.
Autoscaling is powerful and raises some questions:
-
What if I need a global deployment with maximum limits? Select all regions, put autoscaling to on and hit deploy - we will route the traffic to the closest available region and adapt the number of Instances depending on load. In one minute, you get a fault-tolerant, scalable, and globally available deployment.
-
How do I control costs? We give you an immediate cost estimation of the maximum cost of your deployment and you can limit the maximum number of Instances, or completely disable autoscaling.
-
How do I limit regions? You always decide in which region we run your apps and you can even set per-region autoscaling limits.
It was the most requested feature on our feedback platform with new regions. It seems nobody likes to manually adjust the number of instance when there is a sudden spike of traffic in the middle of the night.
Since the inception of Koyeb, we've aimed for a global and serverless experience, one where you don't need to think about the number of servers powering your application and where we dynamically adapt the infrastructure for you depending on load. This is now a reality.
Oh, we announced the GA of Singapore a few hours ago and autoscaling is also available there!
To better understand how autoscaling works, let's dive in and go over a few scenarios.
How it Works
Metrics and decision factors
Autoscaling allows you to define your scaling strategy on up to three metrics to precisely respond to workload changes:
- Requests per second: The number of requests per second per Instance.
- CPU: The CPU usage (expressed as a percentage) per Instance.
- Memory: The memory usage (expressed as a percentage) per Instance.
All autoscaling decisions are taken based on an average of all Instances of a Service on a per-region basis. A spike in Singapore will not affect San Francisco.
Autoscaling checks your deployment every 15 seconds to decide if it needs to scale. However, to maintain stability and avoid rapid changes, once a scaling action is taken, a 1-minute window starts. During this time, no further actions will occur.
When multiple scaling criteria are configured, we calculate the minimum number of Instances required to remain below the target value for each metric. Your Instances are always scaled according to the range you specify.
Example: 10 RPS
To get a concrete understanding of how autoscaling works, let's go over a specific example.
A Service is deployed in the Frankfurt region with the following autoscaling policy:
- Scaling range set to 1 min and 10 max instances
- Set the requests per second (RPS) scaling factor to a target value of 10 RPS
The initial number of requests per second is 5, which is below the target of 10 RPS.
Scale-Up
After 15 seconds, the autoscaling policy is evaluated and the amount of requests per second has now risen to 30. We are above the target and a scale-up action is triggered.
# Current average RPS / target RPS = scaling multiple
30 RPS / 10 RPS = 3 scale multiplier
# Current Instance count * scale multiplier = new Instance count
1 * 3 = 3 Instances
As a result of the autoscaling action, two new Instances are provisioned, putting the total number of running Instances at three.
After one minute, the total number of requests per second across all Instances is observed to be 90. This equals an average of 30 RPS per Instance (90 total RPS / 3 Instances = 30 average RPS per Instance).
# Current average RPS / target RPS = scaling multiple
30 RPS / 10 RPS = 3 scale multiplier
# Current Instance count * scale multiplier = new Instance count
3 * 3 = 9 Instances
Six new Instances are provisioned, taking the total number of running Instances to nine.
Scale-down
At this point, the request per second starts to decrease and, after a cooldown period of one minute, we measure the total number of requests per second across all Instances at 10. This is an average of just 1.11 RPS per Instance (10 total RPS / 9 Instances = 1.11 average RPS per Instance).
# Current average RPS / target RPS = scaling multiple
1.11 RPS / 10 RPS = 0.11 scale multiplier
# Current Instance count * scale multiplier = new Instance count
9 * 0.11 = 1 Instance
Instances will be de-provisioned one at a time, every 60 seconds until we reach a total of one new instance.
The scenario above helps to better understand how Autoscaling works, how the computation is performed, the effects of the cooldown period on downscaling actions, and the behavior during the downscale process.
Getting started with the CLI and control panel
Enabling Autoscaling on your Services is just a CLI command or a one-click action via the control panel.
koyeb app init sky \
--docker koyeb/demo \
--autoscaling-requests-per-second 10 \
--min-scale 2 \
--max-scale 10 \
--regions fra,was,sin
The command above will deploy a new Service named sky in Frankfurt, Washington, D.C., and Singapore with a minimum of 2 and a maximum of 10 Instances.
The Autoscaling policy is set to scale up when the average number of requests per second is above 10 per Instance.
Autoscaling with multiple policies
Adding a new scaling policy can easily be performed by updating the service configuration. We can add a new policy to scale up when the average CPU usage is above 70% and Memory usage is above 75% across all of the Instances.
koyeb service update sky/sky \
--autoscaling-average-cpu 70 \
--autoscaling-average-mem 75
The Service will now automatically scale up and down according to three metrics: CPU, Memory, and Requests per Second.
How to define your Autoscaling policy
To help you define and tune your Autoscaling policy, we natively provide a set of metrics to monitor your service and its usage: CPU, Memory, Response time, Request throughput, and Public data transfer.
Those metrics can be used as a starting point to define your first autoscaling policies and understand how your application behaves.
What's next?
Autoscaling is one of the most important features we've released this year, and we're excited to see how you'll use it to scale your applications.
We're already working on improvements to make autoscaling even better:
- Autoscaling visualization to help understand and track your usage over time
- Scale down to zero to automatically de-provision Instances when your application is not used and reduce costs to zero
- Autoscaling policy assistance to provide recommendations on defining the right policy for your application You can dive deeper by reading the autoscaling documentation.
To get started with autoscaling, you can sign up today and start deploying your first Service today. If you want to dive deeper into autoscaling, have a look at the documentation.
Keep up with all the latest updates by joining our vibrant and friendly serverless community or follow us on X at @gokoyeb.
Happy autoscaling! 🚀