Using Axolotl to Fine-Tune Llama 3 on Koyeb Serverless GPUs
Fine-tuning is a process in ML and AI that involves taking a robust, pre-trained model and further training it on targeted datasets.
It enhances performance and accuracy by customizing a model with domain-specific data, which helps reduce errors and improves overall predictive capabilities—especially in specialized fields like finance, medical advice, or customer support.
In this article, we focus on fine-tuning Llama 3, a model known for its broad language understanding, to excel in the finance domain.
To streamline this workflow, we’ll use Axolotl, an open-source tool that simplifies the entire fine-tuning pipeline. With a single, human-readable YAML file you can configure everything from model selection and training hyperparameters to dataset paths and logging.
Axolotl supports full fine-tuning as well as parameter-efficient methods like LoRA and QLoRA, and it includes performance optimizations—such as Flash Attention and DeepSpeed integration—that scale from a single GPU to multi-node, cloud-based deployments.
Requirements
To successfully complete this tutorial, you will need the following:
- Koyeb Account: Required for accessing Koyeb’s cloud infrastructure, including GPU resources. Create an account at Koyeb if you don’t have one.
- Koyeb GPU Access: Ensure your Koyeb account is enabled for GPU instances so you can fine-tune and deploy GPU-accelerated containers via the Koyeb dashboard.
- Basic Knowledge: You should be comfortable writing and running Python scripts, using Docker to run containers, executing shell commands in the terminal, and working with Jupyter Notebooks, including how to execute shell commands.
Overview of Axolotl’s Features
Axolotl is a specialized fine-tuning framework that streamlines fine-tuning modifications for large language models (LLMs).
It integrates seamlessly with Hugging Face’s ecosystem and supports a variety of fine-tuning methods, enabling both novice and advanced practitioners to efficiently customize models for their tasks.
Model and Method Support
Axolotl supports a diverse range of model architectures and fine-tuning approaches, making it adaptable to many use cases.
Axolotl is compatible with various Hugging Face models such as Llama, Mistral, Falcon, Pythia, and others.
This enables users to choose the model that best fits their use case and resource availability.
The framework offers multiple fine-tuning techniques including:
- Full Fine-Tuning: This traditional method adjusts all model parameters to adapt the pre-trained model to a specific task.
- LoRA (Low-Rank Adaptation): This parameter-efficient approach adds smaller trainable matrices to specific layers, drastically reducing the number of trainable parameters while preserving performance.
- QLoRA (Quantized LoRA): An extension of LoRA that leverages quantization (e.g., 4-bit precision) to further reduce memory footprint, making it viable for lower-resource environments.
These methods allow Axolotl to cater to varied computational requirements—from resource-intensive full fine-tuning on high-end GPUs to efficient adaptations on consumer-grade devices.
Configuration via YAML
A core strength of Axolotl is its use of human-readable YAML configuration files, which encapsulate the entire training setup.
This offers several advantages:
- Centralized Training Setup: All configuration parameters—from model selection and training hyperparameters to dataset paths and logging options—are defined in a single YAML file. This structure simplifies reproducibility and modifications.
- Ease of Customization: Users can adjust settings quickly by editing the YAML file. For instance, switching between fine-tuning methods, tuning hyperparameters like learning rate and batch size, or updating dataset paths becomes straightforward.
- Reducing Complexity: The clear and simple configuration format helps minimize code clutter and debugging efforts, allowing users to focus on optimizing model performance rather than managing infrastructure.
Performance and Scalability
Axolotl is engineered to maximize training performance and scalability, making it suitable for both single GPU setups and large-scale distributed systems:
- Single GPU Efficiency: For smaller projects or performing tests, Axolotl can efficiently run on a single GPU. Its integration with tools like Flash Attention and xformer libraries enhances computation speed and reduces memory overhead on consumer-grade hardware.
- Multi-GPU and Multi-Node Support: Axolotl integrates with distributed training frameworks such as DeepSpeed and Fully Sharded Data Parallelism (FSDP). This enables scaling of fine-tuning workloads across multiple GPUs or nodes, which is critical for training larger models or handling extensive datasets.
- Cloud Readiness: The framework is also optimized for deployment in cloud environments, allowing users to leverage containerized workflows (e.g., running Axolotl in Docker on platforms like Koyeb). This flexibility facilitates rapid scaling and cost-efficient resource utilization.
Preparing Your Dataset
A crucial step before fine-tuning any language model is curating and pre-processing the dataset.
Axolotl supports various dataset formats tailored to different training paradigms, and understanding how to work with these formats can significantly improve your fine-tuning process.
Dataset Formats Supported by Axolotl
Axolotl is designed to work with a range of dataset structures, including:
Instruction Tuning Formats: These datasets consist of samples that include an instruction (or prompt) and an expected response. A common example is the Alpaca format, where each sample typically has fields such as "instruction," "input" (which can be optional), and "output." This format guides the model to understand a specific task or instruction and generate an appropriate response.
Conversation (Chat) Formats: For applications like chatbots or customer support systems, Axolotl supports conversation-based formats. These datasets are structured as multi-turn dialogues where each turn is attributed a role (e.g., system, human, or assistant). ShareGPT is one such format that organizes the dialogue in a conversational sequence, which helps the model learn context and response dynamics in chat interactions.
Raw Text or Custom Formats: When you have a collection of raw text data or a custom format, Axolotl offers flexibility. You can create your own dataset format as long as you can define a clear structure that maps to the training objectives. For instance, you might pre-process raw text into sequences that include start-of-sequence and end-of-sequence tokens to delineate input and output segments.
Pre-processing Guidelines and Tips
To ensure your dataset is ready for fine-tuning with Axolotl, consider the following guidelines:
Consistency is Key: Make sure that the structure of your dataset is consistent throughout. Inconsistent formatting (e.g., missing fields or varying prompt templates) can lead to unexpected behaviors during training. For instruction tuning, ensure that each sample uniformly includes an instruction and a corresponding expected output.
Tokenization Considerations: If you are working with pre-tokenized datasets, verify that they are compatible with the tokenizer of the base model you intend to fine-tune. Axolotl typically expects to perform tokenization using the model’s tokenizer to maintain vocabulary alignment. Pre-tokenized datasets can be used as long as the tokenization process remains consistent and adheres to the model's requirements.
Data Cleaning and Augmentation: Prior to running the fine-tuning process, it is beneficial to clean your data. This may include deduplicating entries, filtering out low-quality or noisy samples, and augmenting the dataset if necessary. High-quality, diverse data directly contributes to better model performance.
Leverage Axolotl’s Pre-processing Tools: Axolotl provides a pre-processing command that can help convert your raw or custom datasets into a standardized format required for training. Running this pre-processing step allows you to inspect the "flattened" data in the expected training format (for example, as a JSONL file where each record is a formatted string with special tokens) so you can make any necessary adjustments before training starts.
Configuring Your Fine-Tuning Job
Fine-tuning a model using Axolotl involves careful configuration through a YAML file.
This file serves as the single source of truth that defines model settings, training parameters, dataset paths, and method-specific options.
In this section, we break down the configuration file structure, discuss key parameters to customize, and walk through a practical example for fine-tuning a Llama model.
Understanding the YAML Configuration
The YAML configuration file is structured into several key sections:
Model Settings: This section defines which base model to use, its associated tokenizer, and any model-specific flags. Important keys in this section include:
base_model: Name of the pre-trained model (e.g.,NousResearch/Llama-3.2-1B).model_type: The architecture type (e.g.,LlamaForCausalLM).tokenizer_type: The corresponding tokenizer (e.g.,LlamaTokenizer).- Other flags such as
is_llama_derived_modelwhich helps the framework adjust internal processes based on the model's lineage.
Training Parameters: These settings control the fine-tuning process itself:
- Hyperparameters: Keys like
learning_rate,num_epochs,micro_batch_size, andgradient_accumulation_stepsdefine how the model learns during training. - Precision Settings: Options such as
fp16,bf16, or enabling quantized training viaload_in_4bitorload_in_8bithelp manage memory consumption and speed. - Optimization Options: The choice of optimizer (e.g.,
adamw_bnb_8bit) and learning rate scheduler (e.g.,cosine) directly affect model convergence and performance. - Miscellaneous Training Flags: Additional parameters like
gradient_checkpointinghelp reduce memory usage, especially when fine-tuning very large models. - Dataset Paths: This section lists where to fetch the training and validation datasets. It generally includes:
datasets: An array specifying each dataset’s path and type (e.g., instruction-tuning format, conversation format).dataset_prepared_path: A directory for storing or retrieving preprocessed data.val_set_size: Determines what fraction of your data will be set aside for validation.
Key Parameters to Customize
Fine-Tuning Approach
Axolotl allows you to choose between two main approaches:
Full Fine-Tuning: Adjusts every parameter in the model. This method can yield excellent performance but is computationally expensive.
Parameter-Efficient Fine-Tuning (PEFT) Methods: Techniques like LoRA minimize the number of trainable parameters by inserting small adapter layers.
Adjust options such as lora_r (the adapter rank), lora_alpha (scaling factor), and lora_dropout (regularization rate). Choosing between full fine-tuning and PEFT methods will depend on your resource constraints and the desired level of model adaptation.
Hyperparameter Adjustments
The following hyperparameters are critical to tune for optimal performance:
Learning Rate: A lower learning rate might yield a more stable training process, especially with parameter-efficient methods.
Batch Size and Gradient Accumulation: These settings control the training throughput. A smaller micro-batch size combined with higher gradient accumulation steps can help when GPU memory is limited.
Number of Epochs vs. Max Steps: These determine how many times the model sees the entire dataset. They can be adjusted based on dataset size and desired convergence.
Practical Example: Fine-Tuning Llama with a YAML Configuration File
Below is a sample YAML configuration file for fine-tuning the Llama model using LoRA:
# Model Settings
base_model: 'NousResearch/Llama-3.2-1B' # Name of the Hugging Face model repository.
model_type: LlamaForCausalLM # Specifies the architecture to be used.
tokenizer_type: LlamaTokenizer # Tokenizer compatible with the base model.
is_llama_derived_model: true # Flag indicating Llama-based architecture.
# Precision and Memory Options
load_in_8bit: false # Disable 8-bit quantization.
load_in_4bit: true # Enable 4-bit quantization for low-memory training.
strict: false # Disable strict loading to allow slight mismatches.
# Dataset Configuration
datasets:
- path: 'datasets/alpaca_format.jsonl' # Path to dataset in an instruction tuning format.
type: alpaca # Specifies the dataset format.
dataset_prepared_path: 'preprocessed_data' # Location for preprocessed datasets.
val_set_size: 0.1 # Reserve 10% of data for validation.
# Fine-Tuning Method and Adapter Settings
adapter: lora # Use LoRA for parameter-efficient fine-tuning.
lora_model_dir: '' # Leave blank for fresh fine-tuning.
lora_r: 16 # Adapter rank: lower rank means fewer trainable parameters.
lora_alpha: 32 # Scaling factor, typically 2x the adapter rank.
lora_dropout: 0.05 # Dropout rate for the adapter layers.
lora_target_modules: # Specific modules within the model to apply LoRA.
- 'q_proj'
- 'v_proj'
- 'o_proj'
# Training Hyperparameters
gradient_accumulation_steps: 4 # Number of mini-batches to accumulate before an update.
micro_batch_size: 2 # Batch size per GPU.
num_epochs: 3 # Total training epochs.
optimizer: adamw_bnb_8bit # Optimizer choice tailored for efficiency.
lr_scheduler: cosine # Learning rate scheduler to control decay.
learning_rate: 0.0002 # Initial learning rate.
# Additional Training Options
train_on_inputs: false # Do not include input text in the loss computation.
group_by_length: false # Disable grouping by input length.
fp16: true # Enable 16-bit floating point precision for faster training.
gradient_checkpointing: true # Save memory by re-computing intermediate activations.
logging_steps: 10 # Log training metrics every 10 steps.
Each section is annotated with comments to explain its purpose:
Model Settings: The configuration begins by setting the base model to NousResearch/Llama-3.2-1B, defining the model type and tokenizer, and specifying that the model is derived from Llama.
Precision Options: Here, 4-bit quantization is enabled (load_in_4bit: true) to reduce memory usage, a useful option when working with limited computational resources.
Dataset Setup: The dataset is provided in the Alpaca format (instruction tuning). A dedicated folder for preprocessed data is specified, with 10% of the dataset reserved for validation.
Fine-Tuning Method: LoRA is chosen as the adapter method. The key parameters (lora_r, lora_alpha, and lora_dropout) are set to control the size and regularization of the adapter layers, and specific target modules for LoRA are listed.
Training Hyperparameters: The configuration details the optimizer, learning rate scheduler, and fundamental training parameters such as micro-batch size, epochs, and gradient accumulation. Precision is handled with half-precision (fp16) mode and memory is optimized using gradient checkpointing.
Running Your First Fine-Tuning Job
Getting started with fine-tuning a model using Axolotl is straightforward once your environment and configurations are set up, see the Use Case section below for how to set up Axolotl with a Koyeb GPU.
In this section, we describe the full process of how to fetch example configurations, launch your first training job, and monitor its progress.
Fetching Examples
Axolotl’s repository includes a collection of example configuration files that demonstrate various fine-tuning scenarios.
These examples are invaluable for learning the setup process and provide a solid starting point for your own experiments.
To fetch the examples:
axolotl fetch examples
These examples typically include YAML configuration files for different fine-tuning methods (full fine-tuning, LoRA, QLoRA, etc.) and model types.
Reviewing these examples can help you understand the structure of the configuration file and determine which settings best suit your intended use case.
Starting the Training Process
With your example configuration file ready, you can launch your first fine-tuning job.
For instance, if you have an example YAML file for training Llama with LoRA located at examples/llama-3/lora-1b.yml, you can start the training process with the following command:
axolotl train examples/llama-3/lora-1b.yml
The example configuration (lora-1b.yml) includes settings for model architecture, dataset paths, hyperparameters, and the adapter method, all of which determine how the fine-tuning job will proceed.
Launching your training job with an example file allows you to verify that your system and configuration are correctly set up, and it gives you a clear reference for how a complete fine-tuning process is executed.
Monitoring Progress
Once the training job is running, it is important to keep an eye on its progress.
Here are some tips for monitoring training logs and performance metrics effectively:
Logging and Metrics:
- Axolotl outputs training logs to the console. These logs typically include loss values, learning rate updates, and other relevant metrics.
- For more detailed tracking, consider integrating with logging platforms like Weights & Biases (W&B) or MLflow. This integration allows you to visualize progress through dashboards and historical run comparisons.
Checkpointing:
- Regular checkpoint saving (controlled by parameters such as
logging_stepsorsaves_per_epoch) is helpful for both monitoring progress and recovering from any potential interruptions. Check your output directory to view saved checkpoints.
Progress Indicators:
- Look for periodic printouts in the terminal that indicate the current epoch, step, or batch number.
- Monitor the training loss curve to ensure that the loss is decreasing as expected. An unexpected plateau or increase could signal issues with your learning rate or other hyperparameters.
Resource Utilization:
- Keep an eye on GPU usage and memory consumption using system monitoring tools or built-in commands like
nvidia-smi. This helps ensure that your hardware resources are being effectively utilized without overloading them.
Debugging Options:
- If you run into issues, Axolotl offers a debug mode (via configuration settings) that can provide more detailed output to help identify problems during data pre-processing or training.
Post-Training: Inference and Merging
Once the fine-tuning process is complete, the next steps involve evaluating the fine-tuned model, merging any adapter layers with the base model, and saving the results for future inference or deployment.
This section outlines how to evaluate your model on new data, merge outputs and checkpoints.
Model Evaluation
Evaluating your fine-tuned model is crucial to ensure it generalizes well to new data and meets your performance expectations.
Here’s how to effectively evaluate your fine-tuned models:
Testing on New Data: Create or use an existing validation dataset that is separate from the training data. This dataset should reflect the typical input your model will encounter:
axolotl inference examples/llama-3/lora-1b.yml --lora-model-dir="./outputs/lora-out"
This command utilizes your fine-tuned model from the specified directory (e.g., ./outputs/lora-out) to generate predictions for the provided inputs.
Metric Monitoring: Utilize metrics such as loss, accuracy, BLEU score (for translation tasks), or any custom evaluation metric that aligns with your business objective. Monitoring these metrics during evaluation helps you gauge how well the model adapts to new situations.
Qualitative Analysis: In addition to quantitative metrics, conduct a qualitative analysis by manually reviewing model outputs. This is particularly valuable in language generation tasks where the nuance and context matter.
Merging and Saving Models
After evaluation, it’s common practice to merge the training outputs or checkpoints into a final model file that encapsulates all the fine-tuning adjustments.
Follow these steps to merge and save your model:
Merging Checkpoints: Fine-tuning with parameter-efficient methods (e.g., LoRA or QLoRA) usually results in adapter weights that are stored separately from the base model. To deploy your model, you need to merge these adapter weights back into the pre-trained base model:
axolotl merge-lora examples/llama-3/lora-1b.yml --lora-model-dir="./outputs/lora-out"
This command combines your LoRA adapter with the base model to produce a single merged model file.
Saving the Final Model: Once merged, save the final model to a designated output directory. This model can then be used for inference in production or shared with the broader community by deploying to Hugging Face, for example.
You can automatically deploy to Hugging Face by adding the following command to the .yml file:
# Automatically upload checkpoint and final model to HF
hub_model_id: username/custom_model_name
Documentation and Backup: It’s a good practice to maintain clear documentation of the merging process and keep backups of intermediate checkpoints. This allows you to revert or analyse different stages if further debugging or fine-tuning is needed later.
Use Case: Enhancing Llama with Financial Customer Support Data
Fine-tuning large language models for financial customer support applications can provide a tailored, efficient, and data-driven solution that addresses the unique challenges of the finance industry.
By adapting the model to understand industry-specific terminologies, compliance requirements, and customer expectations, financial institutions can offer secure, precise, and responsive support.
This section explains why fine-tuning for financial customer support is advantageous, outlines the key implementation steps, and discusses the real-world benefits of deploying such specialized chatbots.
Why Fine-Tune for Financial Customer Support
Customizing a language model for financial services offers several advantages that are critical in this highly regulated and detail-oriented domain:
Tailored Responses with Financial Expertise: By fine-tuning on historical support data—such as customer inquiries related to investment products, account management, loan applications, or regulatory queries—the model can generate responses that not only reflect your brand's unique voice but also accurately address complex financial topics. This ensures that customers receive advice aligned with industry standards and compliance guidelines.
Efficiency and Consistency: In a financial institution, consistency is key. A fine-tuned model can provide prompt and standardized responses across a wide range of queries—from daily account questions to high-stakes investment advice—thereby enhancing reliability. This consistent performance reduces response times and minimizes errors, which is crucial in a sector where precision is paramount.
Data-Driven Improvements for Financial Processes: Utilizing historical customer support interactions enables the model to identify and learn from common financial issues and queries. Fine-tuning on such specialized data helps the model to handle frequently asked questions (FAQs) related to fees, rates, transaction disputes, and compliance issues, ultimately reducing manual intervention and streamlining support operations.
Implementation Steps
To fine-tune a Llama model on financial customer support data, follow these essential steps.
Deploy to Koyeb
First, let's start by preparing our training environment on Koyeb.
In the Koyeb control panel, while on the Overview tab, initiate a new service creation by clicking Create Service. You can select a Web service application.
Make sure to follow and prepare these configurations:
- Select Docker as your deployment method.
- For the Docker image, enter
axolotlai/axolotl-cloud:main-latest - Select the GPU you wish to use, for example,
A100. Training will work on other GPUs, but an A100 is recommended for optimal performance and speed. - On the Environment Variables section, add
JUPYTER_PASSWORDas the name and in the value type in your desired password (this will control access to the Jupyter notebooks) - In the Exposed Ports section, make sure to update the port number to
8888 - In the Service name section, choose an appropriate name.
- Finally, click Deploy.
Note: Here we are using the cloud version of Axolotlai because it will automatically start a Jupyter notebook, make it easier to access the server and run the commands.
Training Dataset
For training dataset we are going to use this financial dataset from Hugging Face, which will keep our configurations simple:
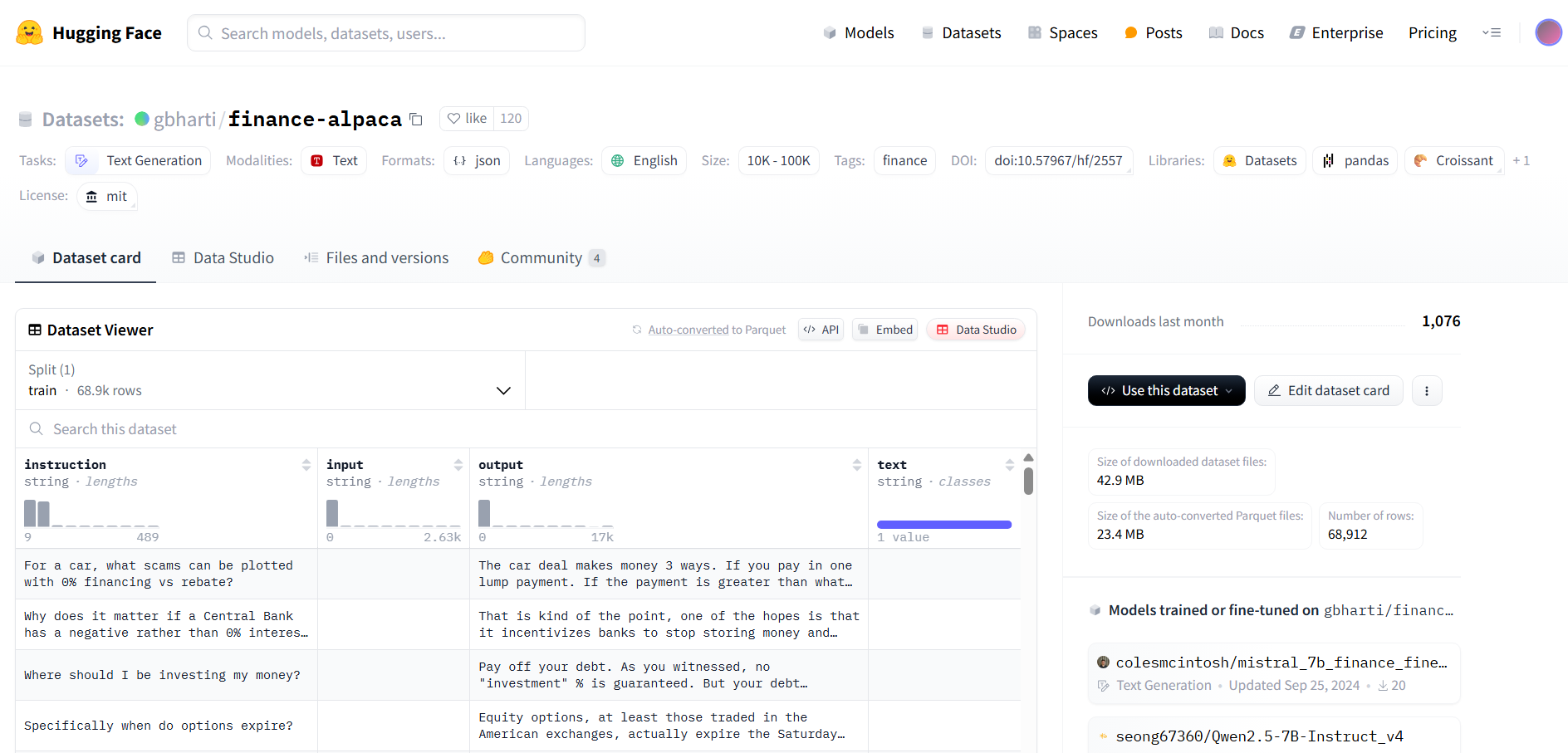
Jupyter Notebook
With the deployment now finished and the dataset selected and prepared, we can now access our Jupyter notebook.
Open in the browser the link associated with your web service application, check your service details in the Koyeb control panel.
You will be required to type in the password that you defined previously:
After logging in, you will be taken to the Jupyter Launcher where you can open a Terminal session:
We can now run the commands that were described in the previous sections to prepare the yml file, train and evaluate the model.
Let's start by downloading the examples, so we can have a base yml file:
axolotl fetch examples
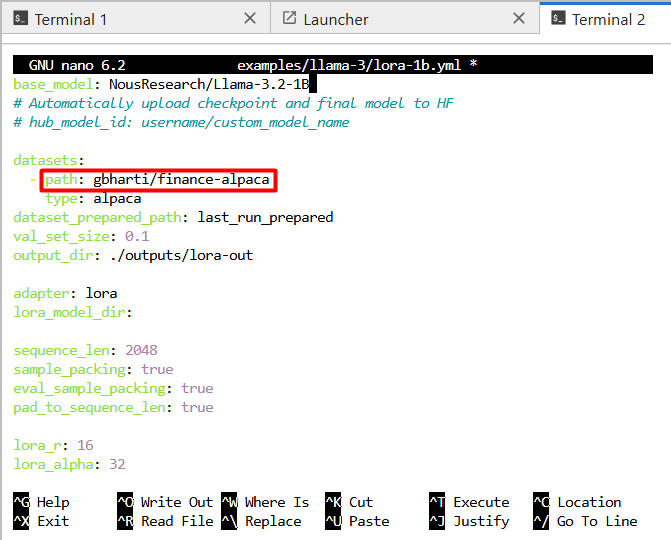
Then, you will need to edit the example yml file for Llama3 with Lora, with the command:
nano examples/llama-3/lora-1b.yml
Using the 1B model reduces the memory and time necessary to run this example.
Change the dataset path to gbharti/finance-alpaca as show in the screenshot:
Press CTRL+X to exit and Y to confirm saving the changes to the file.
Next step is to start the training of the model, which is done with command:
axolotl train examples/llama-3/lora-1b.yml
After the processing starts and stabilizes, you can have an idea of the expected duration. As defined in the yml file, periodically checkpoints will be saved at 25%, 50% and 75%:
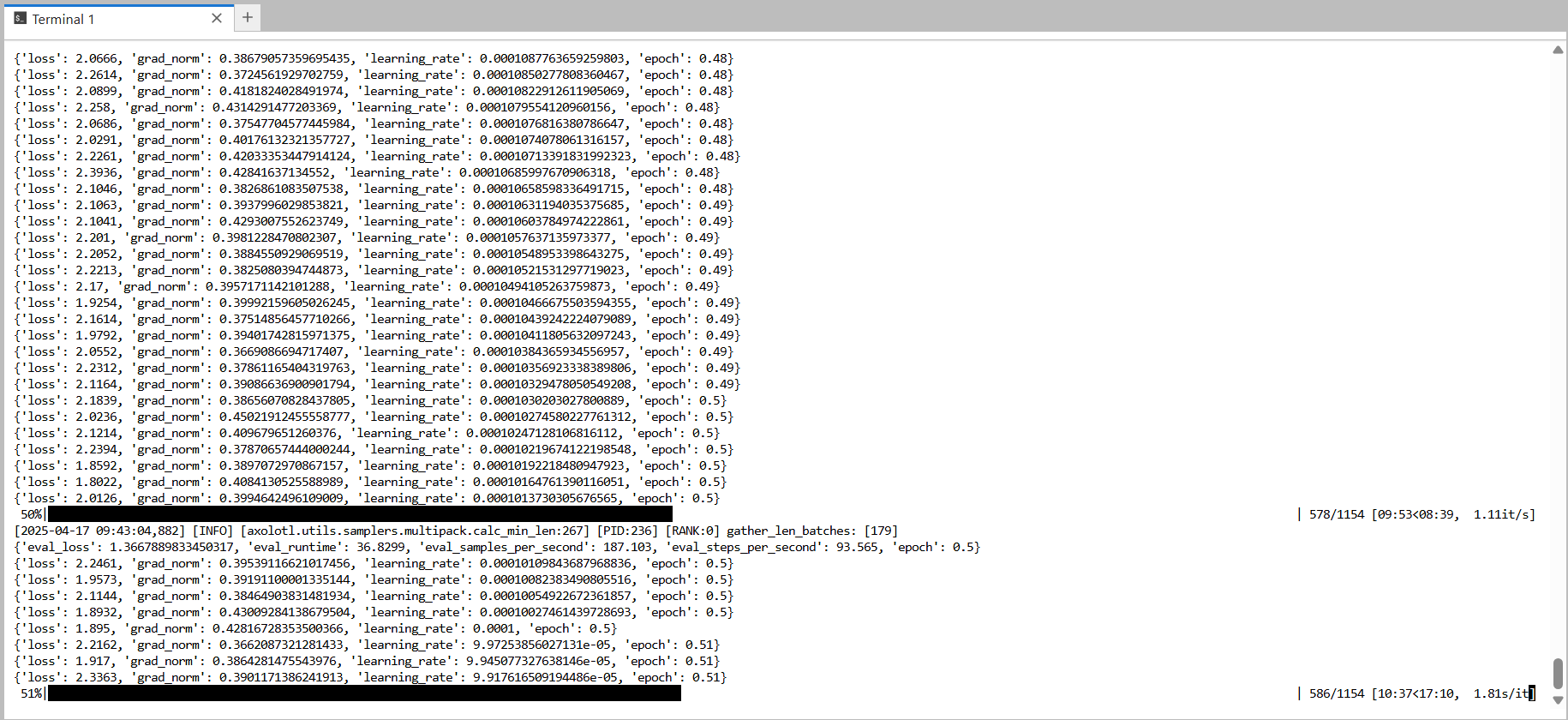
After the training is complete, we can now evaluate the new fine-tuned model.
But first, we start by running the "normal" model:
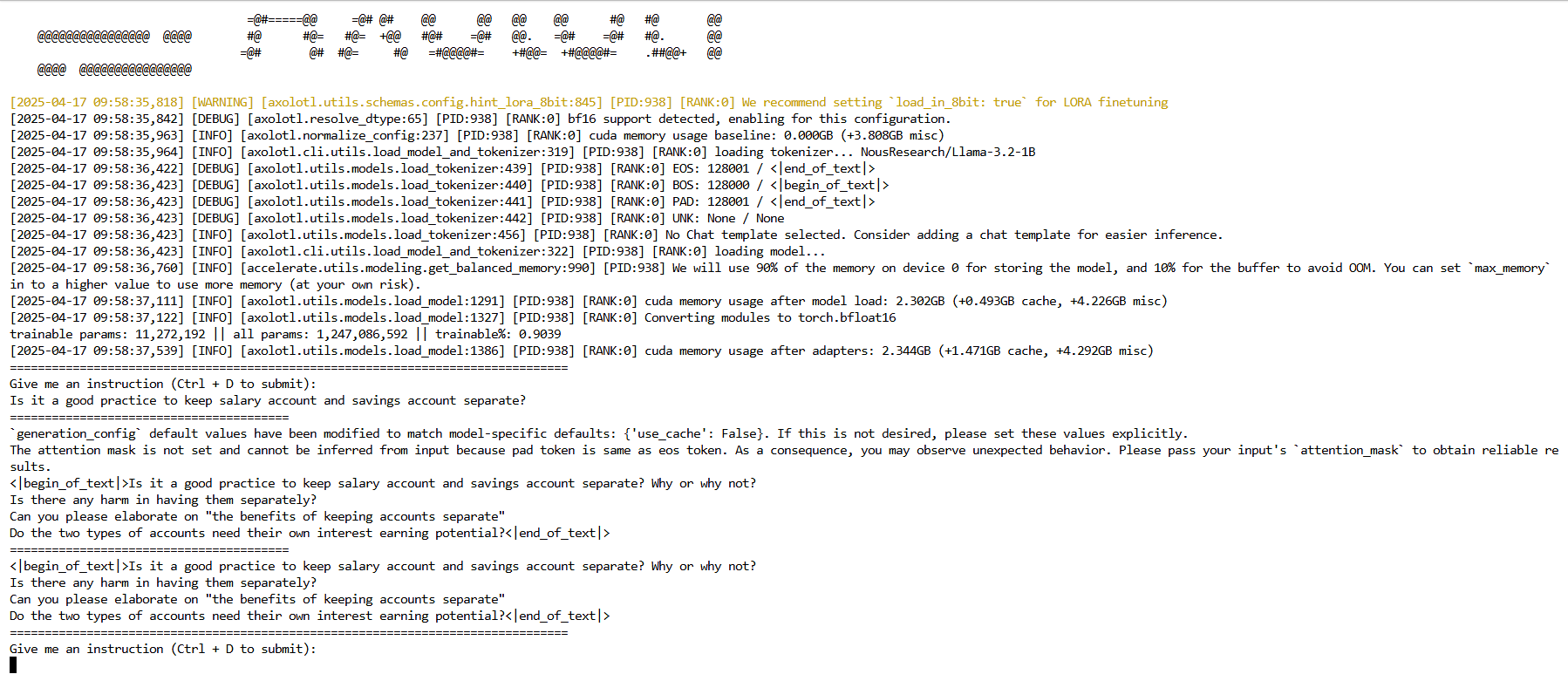
axolotl inference examples/llama-3/lora-1b.yml
You can type in an instruction at the prompt and press CTRL-D to execute it:
Is it a good practice to keep salary account and savings account separate?
After a couple of seconds the model response will be displayed. As you can see, it doesn't have a lot of knowledge:

But of course, we already knew that and just fine-tuned it for improving its domain knowledge.
Let's now run the fine-tuned model with:
axolotl inference examples/llama-3/lora-1b.yml --lora-model-dir="./outputs/lora-out"
Note: As you can see, the command is very similar to the previous one, but in this one we are specifying the trained model files with lora-model-dir.
Again, type an instruction and press CTRL-D to execute it:
Is it a good practice to keep salary account and savings account separate?
This time, the fine-tuned model shows a more extensive knowledge:
As a final note, if you wish to automatically publish the fine-tuned model to Hugging Face at the end of the training process, just edit this line in the yml file:
hub_model_id: username/custom_model_name
Make sure to replace username with your HF username and fill in custom_model_name with your desired model name.
Note: Before running the train command, make sure to login to Hugging Face with:
huggingface-cli login
Follow the instructions to generate and copy/paste in the generated token. Make sure to select at least permission to ‘Write access to contents/settings of all repos under your personal namespace’.
You can find the model fine-tuned when writing this article at: DevAsService/Llama-3.2-1B-Finance.
Real-World Benefits
Fine-tuning a financial customer support model with industry-specific data can yield significant competitive and operational benefits:
Enhanced Customer Satisfaction: Customers receive accurate, timely, and compliant responses that reflect the institution’s dedication to security and reliability in handling financial matters. This tailored approach fosters greater trust and encourages long-term engagement.
Reduced Operational Costs: Automating routine financial inquiries and streamlining support processes lowers the operational overhead, allowing human agents to focus on complex issues and strategic decision-making. The resulting cost savings can be reinvested in further digital innovations and customer service improvements.
Competitive Edge: A finely tuned financial model provides a high-quality, consistent support experience that distinguishes your institution from competitors. By delivering expert guidance on intricate financial topics, the model not only meets but exceeds customer expectations.
Tips, Tricks, and Troubleshooting
Fine-tuning large language models is a complex task that benefits immensely from following best practices and having a robust troubleshooting strategy.
In this section, we provide advice on selecting the right training method, adjusting hyperparameters, and optimizing performance, along with troubleshooting tips drawn from Axolotl’s extensive FAQ and debugging guides.
Before starting a training job, assess your use case and available resources.
Depending on your scenario, you may opt for full fine-tuning—updating all parameters when ample GPU resources are available—or choose parameter-efficient methods like LoRA or QLoRA to conserve memory.
Key points to consider include:
- Full Fine-Tuning: Best when you have extensive hardware capacity and need comprehensive model adaptation.
- LoRA/QLoRA: Ideal for limited-resource environments; these methods minimize the number of trainable parameters.
- Hyperparameter Tuning: Experiment with different learning rates, batch sizes, and gradient accumulation settings to find the optimal balance.
Performance optimizations can greatly enhance training efficiency. Incorporate hardware-optimized libraries and distributed training frameworks to reduce training time and memory requirements.
For example, you can leverage:
- Flash Attention: Accelerates the attention mechanism while lowering memory usage.
- Multi-GPU/Distributed Training: Utilize frameworks like DeepSpeed or Fully Sharded Data Parallelism (FSDP) to manage distributed workloads efficiently.
- Gradient Checkpointing: Saves memory by recomputing intermediate activations during the backward pass.
Even with careful planning, issues may arise during fine-tuning, often related to data pre-processing or configuration inconsistencies.
To troubleshoot effectively:
- Data Verification: Run Axolotl’s pre-processing commands in debug mode to inspect and confirm the dataset structure.
- Configuration Checks: Double-check your YAML file for typos or conflicting parameters, especially regarding hardware optimizations.
- Memory Management: If you experience crashes or slow training, consider reducing the batch size or disabling non-essential features temporarily.
- Community Resources: Consult the Axolotl FAQ and debugging guides, and leverage forums like Discord or GitHub for additional insights.
Conclusion
In this guide, we covered the entire process of fine-tuning large language models using Axolotl—from installation and environment setup to dataset preparation, configuration via YAML, and launching the training job.
We demonstrated how to preprocess data for various formats, customize key hyperparameters, and effectively run a fine-tuning process with example configuration files, providing a robust foundation to adapt models for your specific tasks.
Additionally, we detailed the post-training steps, including model evaluation and merging of adapter weights, so that your fine-tuned model can be deployed or further refined.
As you move forward, experiment with different configurations and fine-tuning methods to discover what works best for your application.
The iterative nature of model development means that each experiment offers insights into model behavior and opportunities for improvement.
By continuously exploring new techniques, adjusting hyperparameters, and refining your dataset, you'll not only improve model performance but also enable it to tackle more complex challenges.

