Using LlamaIndex and MongoDB to Build a Job Search Assistant
Introduction
In today's job market, finding the perfect role often feels like searching for a needle in a haystack. One solution is to use AI-driven chatbots to streamline this process, offering quick responses and personalized assistance.
However, relying solely on full-text search can be limiting, as job descriptions vary widely and users may input non-standard terms. By using AI techniques like Retrieval-Augmented Generation (RAG) with LlamaIndex, you can build chatbots that not only understand the nuances of job description, but also make the job search experience more efficient and human-like.
In this tutorial, you will learn how to integrate LlamaIndex with MongoDB to create an AI-driven job search assistant that not only responds to user queries, but also continuously updates its knowledge base in real time, ensuring accurate and relevant results.
You can consult the project repository as work through this guide. After provisioning the MongoDB database, you can deploy the job assistant application as built in this tutorial using the Deploy to Koyeb button below:

Once deployed, before using the application, you will need to seed at least one initial job (directed at your Koyeb app), and set up MongoDB Atlas vector search.
Note: You will need to replace the values of the environment variables in the configuration with your own OPENAI_API_KEY and MONGODB_URI. Consult the tutorial here to understand the expected values. You can leave the rest of the values as-is.
Requirements
To successfully follow this tutorial, you will need the following:
- Node.js and npm installed. The demo app in this tutorial uses version 18 of Node.js.
- Git Installed.
- An OpenAI account.
- A MongoDB account.
- A Koyeb account to deploy the application.
Demo
Before we jump into the technical stuff, let's look at a sneak peek of what you will be building in this tutorial:
Steps
- Generate an OpenAI token
- Provision a MongoDB database
- Create a new Next.js application
- Build the components of our application
- Define the Next.js application routes
- Deploy the Next.js application to Koyeb
- Conclusion
Generate an OpenAI token
HTTP requests to the OpenAI API require an authorization token. To generate this token, while logged into your OpenAI account, navigate to the API Keys page and click the Create new secret key button after entering name for your token. Copy and securely store this token for later use.
Now, let's move on to creating your MongoDB Database.
Provision a MongoDB database
We will be using MongoDB to store the data associated with our job search application persistently.
To get started, sign into MongoDB and select Database under the Deployment section. Click Build a database to get started with creating your own database.
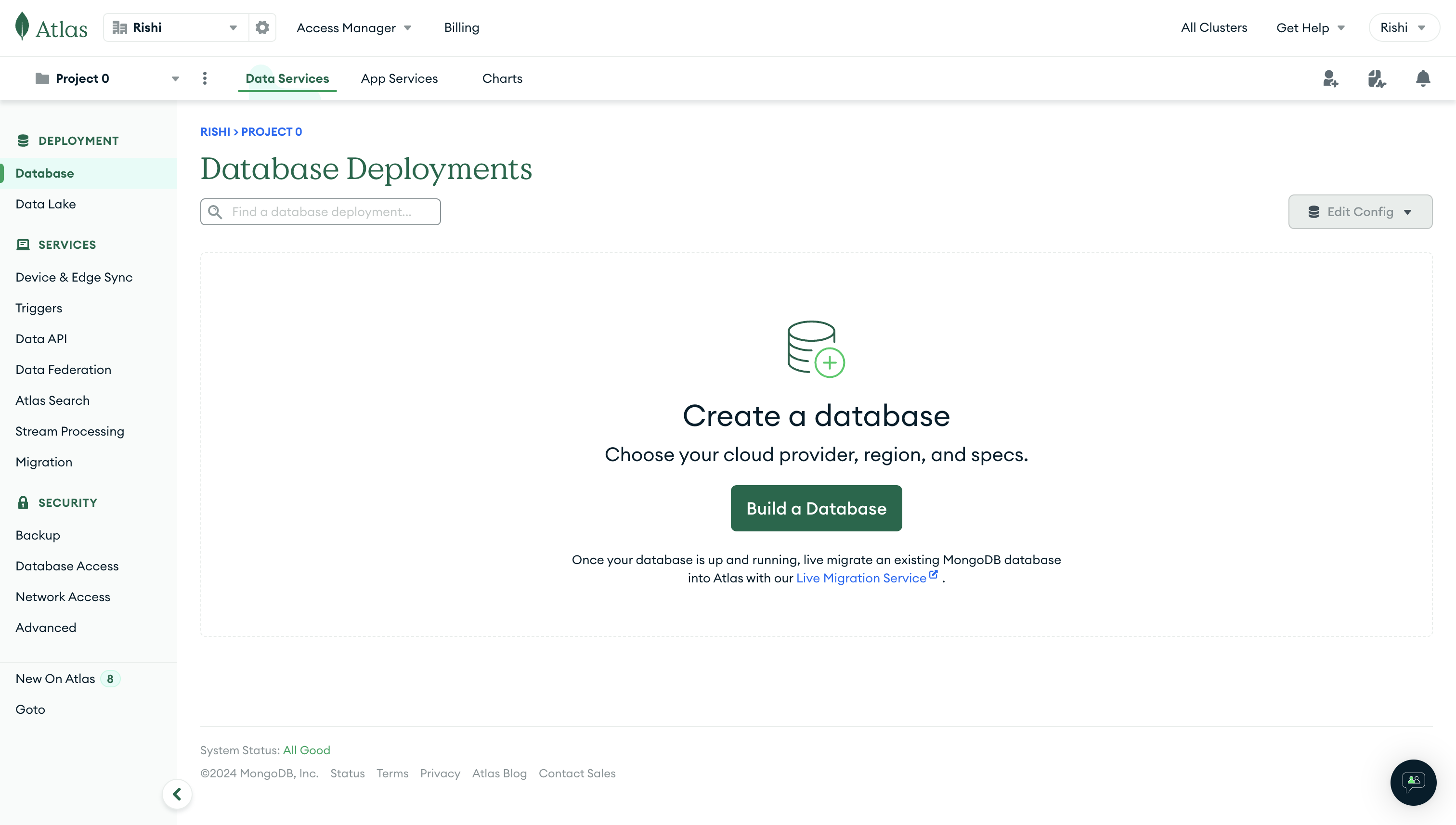
Select M0 as the cluster type, and (optionally) give the cluster a personalized name. Click Create Deployment to proceed.
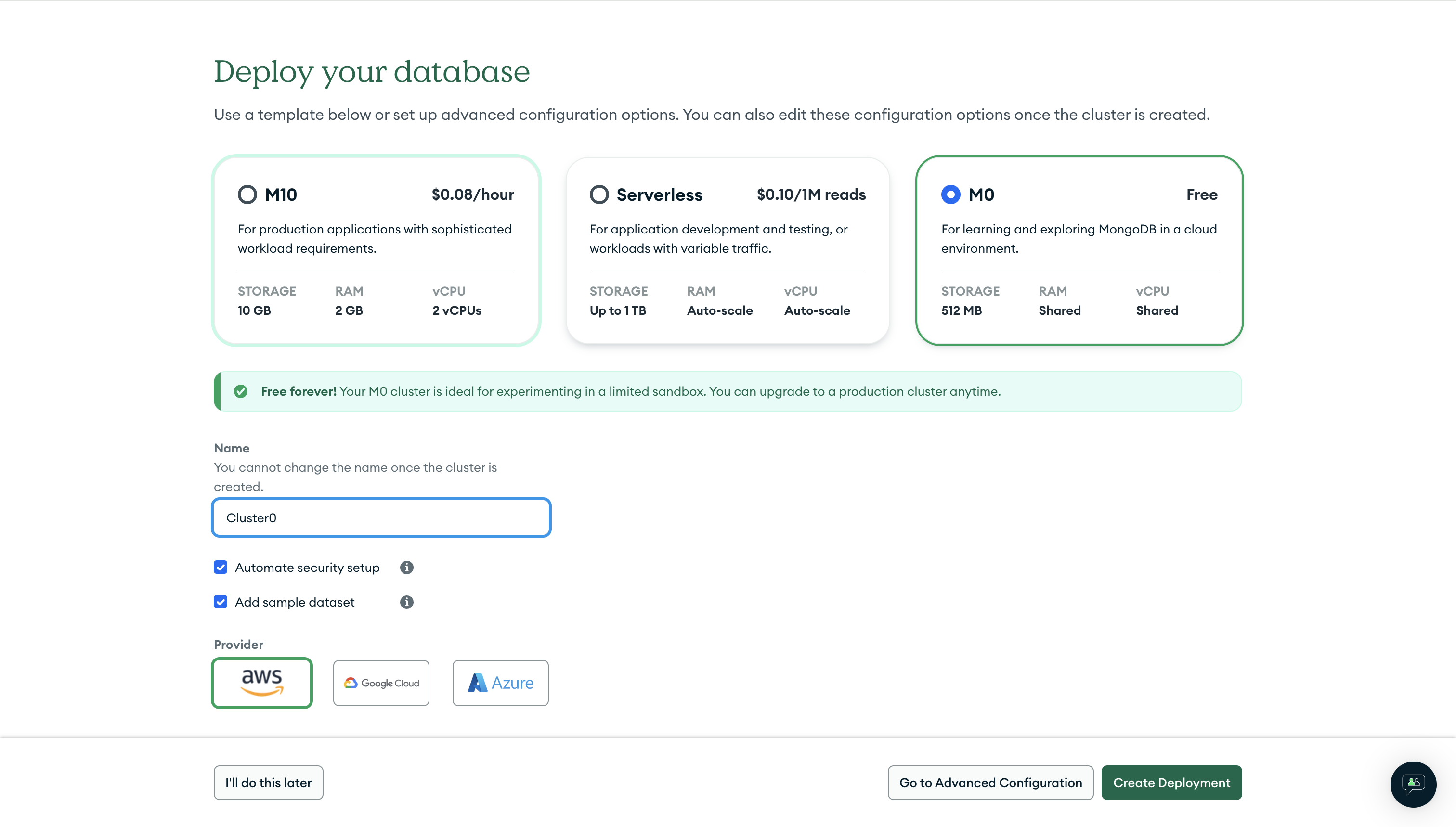
You may be directed to create a database user. Instead of limiting connections to your local IP address, you will want to ensure that all IPs are allowed (0.0.0.0/0) so that your application will work as expected when deployed to Koyeb.
Next, you will be taken to the connection screen. Click Drivers in the Connect to your application section. On the page that follows, with the Node.js driver selected, click the copy icon associated with the MongoDB connection string:
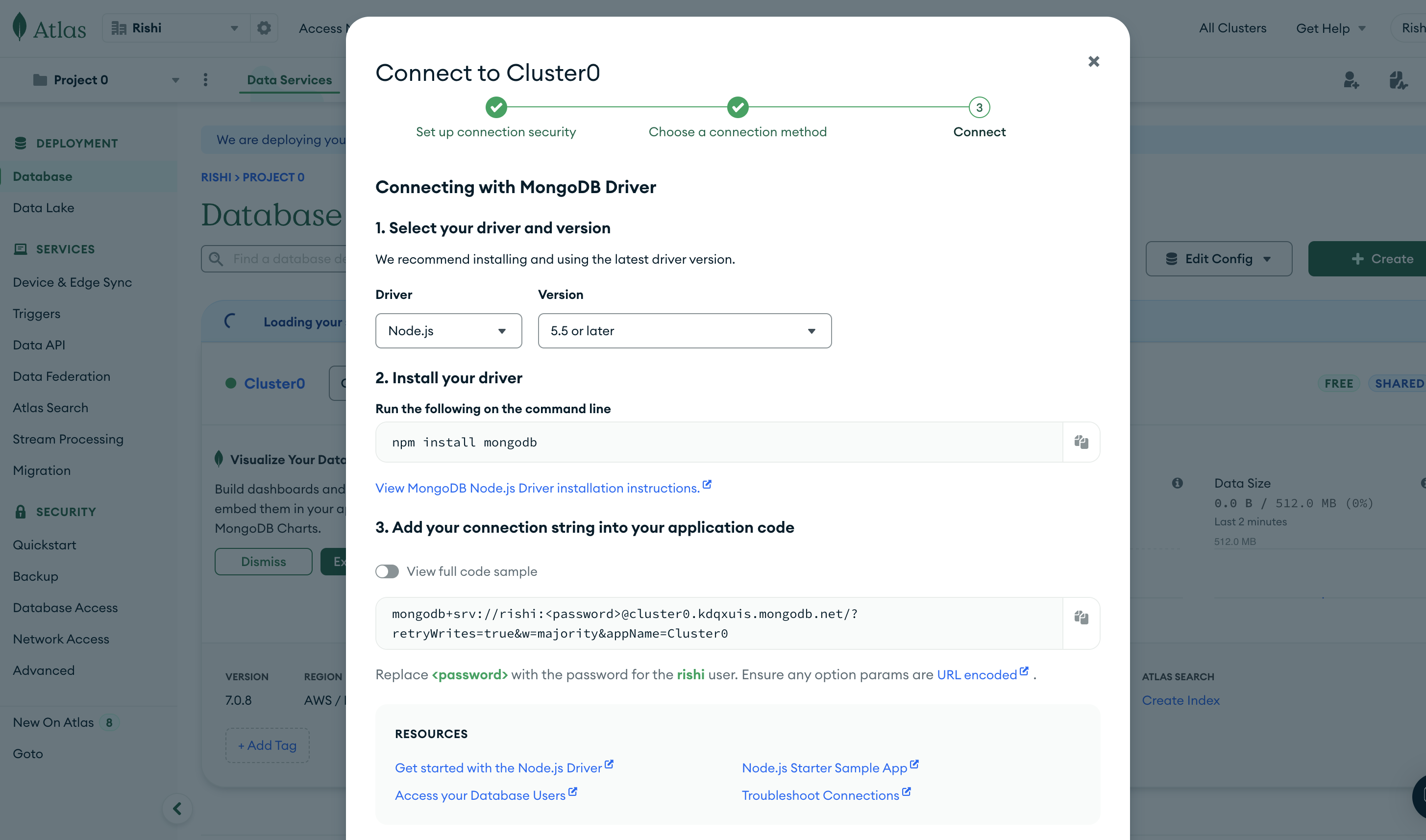
This will copy the connection string with the password for the database user replaced by <password>. If necessary, you can manage and regenerate the password for your user on the Database Access page in the Security section of the left-hand menu.
Save the complete connection string in a safe place for later. Now, let's move on to creating a new Next.js application to interact with your MongoDB database.
Create a new Next.js application
Now that we have our database, let's get started by creating a new Next.js project.
In your terminal, type:
npx create-next-app@latest example-llamaindex-job-search
When prompted, choose:
Yeswhen prompted to use TypeScript.Nowhen prompted to use ESLint.Yeswhen prompted to use Tailwind CSS.Nowhen prompted to usesrc/directory.Yeswhen prompted to use App Router.Nowhen prompted to customize the default import alias (@/*).
Once that is done, move into the project directory and start the app in development mode by executing the following command:
cd example-llamaindex-job-search
npm run dev
The app should be running on localhost:3000. Stop the development server by pressing CTRL-C when you are finished.
Next, create an .env.local file to set up the environment variables the application needs. Replace the values with the OpenAI API key and MongoDB connection string you copied earlier. We'll also take the opportunity to set a few other MongoDB variables that our application will look for later:
# File: .env.local
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
MONGODB_URI="<YOUR_MONGODB_CONNECTION_STRING>"
MONGODB_DATABASE="jobs_db"
MONGODB_VECTORS="jobs_vectors"
MONGODB_VECTOR_INDEX="jobs_vectors_index"
Next.js will automatically load these variables when we start up the application locally.
Next, install the necessary dependencies with the following commands:
npm install llamaindex@0.3.4 mongodb@6.5.0 ai openai
npm install -D @tailwindcss/typography
The command above installs the packages passed to the install command, with the -D flag specifying the libraries intended for development purposes only.
The libraries installed include:
ai: A library to build AI-powered streaming text and chat UIs.mongodb: A driver for Node.js to easily interact with MongoDB databases.llamaindex: A data framework for creating LLM applications.openai: A library to conveniently access OpenAI's REST API.
The development-specific libraries include:
@tailwindcss/typography: A set of prose classes to style HTML elements (built from markdown).
Now, let's move on to creating components that will help you quickly prototype the UI and handle the complexities of creating a chatbot application with Next.js.
Build the components of our application
Configure shadcn/ui components
With shadcn/ui you will be able to use baked-in accessible <input> and <button> elements. Execute the command below to start setting up the shadcn/ui:
npx shadcn-ui@latest init
You will be asked a few questions to configure a components.json, answer with the following:
✔ Would you like to use TypeScript (recommended)? no / **yes**
✔ Which style would you like to use? › **Default**
✔ Which color would you like to use as base color? › **Slate**
✔ Would you like to use CSS variables for colors? no / **yes**
With above, you have set up a CLI that allows us to easily add React components to your Next.js application.
Before moving on, insert the following code in tailwind.config.ts to load the prose classes we installed earlier. Initializing shadcn/ui rewrites the tailwind.config.ts file, so we needed to defer this step until the file was in its current state:
// File: tailwind.config.ts
import type { Config } from "tailwindcss";
const config = {
// Rest of the file as-is
plugins: [
require("tailwindcss-animate") // [!code --]
require("tailwindcss-animate"), // [!code ++]
require("@tailwindcss/typography") // [!code ++]
],
} satisfies Config
export default config
Execute the command below to get the button and input elements:
npx shadcn-ui@latest add button
npx shadcn-ui@latest add input
With the above, a ui directory should now exist inside the components directory containing button.tsx and input.tsx files.
Create a markdown component
For our application, we want to render the streaming markdown compatible responses from AI in a visually appealing manner. For this, you will use react-markdown library. Install it with the following command:
npm install react-markdown
Afterwards, create a markdown.tsx file inside the components directory with the following code:
// File: components/markdown.tsx
import clsx from "clsx";
import ReactMarkdown from "react-markdown";
interface MarkdownProps {
index: number;
message: string;
}
const Markdown = ({ message, index }: MarkdownProps) => {
return (
<ReactMarkdown
components={{
a({ children, href }) {
return (
<a href={href} target="_blank" className="underline text-black">
{children}
</a>
);
},
}}
className={clsx(
"w-full mt-4 pt-4 prose break-words prose-p:leading-relaxed prose-pre:p-0",
index !== 0 && "border-t"
)}
>
{message}
</ReactMarkdown>
);
};
export default Markdown;
The code above imports the react-markdown library and uses it to style each HTML element.
Now, let's move to create the routes for the user-facing pages and API endpoints.
Define the Next.js application routes
To create interactive, user-facing pages in Next.js, you will use Next.js Client Components to create an interactive UI that is pre-rendered on the server and run with JavaScript the browser.
To create API endpoints in Next.js, you will use Next.js Route Handlers to serve responses via the web response API.
The structure below is what our app directory will look like at the end of this section:
├── page.tsx
├── api/
├────── chat/
├───────── route.ts
├────── train/
└───────── route.ts
page.tsxwill serve as the index route, i.e.localhost:3000.api/chat/route.tswill serve responses forlocalhost:3000/api/chat.api/train/route.tswill serve responses forlocalhost:3000/api/train.
| URL | Matched Routes |
|---|---|
/ | app/page.tsx |
/api/chat | app/api/chat/route.ts |
/api/train | app/api/train/route.ts |
Create a job indexing API endpoint
First, create a directory named mongo inside the lib directory with the following command:
mkdir lib/mongo
Then, create a file named instance.server.ts with the following code to setup a MongoDB client for your database:
// File: lib/mongo/instance.server.ts
import { MongoClient } from 'mongodb'
export const databaseName = process.env.MONGODB_DATABASE as string
export const indexName = process.env.MONGODB_VECTOR_INDEX as string
export const vectorCollectionName = process.env.MONGODB_VECTORS as string
export const client = new MongoClient(process.env.MONGODB_URI as string)
In the code above, you have set up a MongoDB client instance using the MongoClient class and MONGODB_URI environment variable. Additionally, you have exported 3 variables representing the database, collection, and vector index names of your MongoDB instance as we configured earlier in the .env.local file.
Now, create a file named store.server.ts in the same directory with the following code to setup MongoDB Atlas Vector Search client for your MongoDB instance:
// File: lib/mongo/store.server.ts
import { MongoDBAtlasVectorSearch } from 'llamaindex/storage/vectorStore/MongoDBAtlasVectorStore'
import {
vectorCollectionName as collectionName,
databaseName as dbName,
indexName,
client as mongodbClient,
} from '@/lib/mongo/instance.server'
export default new MongoDBAtlasVectorSearch({
mongodbClient,
dbName,
indexName,
collectionName,
})
In the code above, we export a MongoDBAtlasVectorSearch instance, configured with the MongoDB client, database name, index name, and collection name. It integrates with LlamaIndex's MongoDBAtlasVectorStore to facilitate vector storage and search functionalities within your Next.js application.
Using both of the above files, you can now create an endpoint that allows you to insert jobs data and index them for vector search simultaneously.
Create the app/api/train directory structure by typing:
mkdir -p app/api/train
Inside the new directory, create a new file called route.ts with the following content:
// File: app/api/train/route.ts
import { Document, VectorStoreIndex, storageContextFromDefaults } from 'llamaindex'
import { NextRequest, NextResponse } from 'next/server'
import { client, databaseName, vectorCollectionName } from '@/lib/mongo/instance.server'
import vectorStore from '@/lib/mongo/store.server'
// File: app/api/train/route.ts
export const runtime = 'nodejs'
export async function POST(request: NextRequest) {
try {
const { jobs } = await request.json()
// Get MongoDB database and collection
const db = client.db(databaseName)
const collection = db.collection(vectorCollectionName)
// Insert all jobs from the request in MongoDB
await collection.insertMany(jobs)
// Create LlamaIndex Text Documents containing job data as Metadata
const documents = jobs.map(
(job: Record<any, any>) =>
new Document({
// Use the job description
text: job.job_description,
// Attach metadata as the job JD
metadata: JSON.parse(JSON.stringify(job)),
})
)
// Index all the Text Documents in MongoDB Atlas
const storageContext = await storageContextFromDefaults({ vectorStore })
await VectorStoreIndex.fromDocuments(documents, { storageContext })
return NextResponse.json({ code: 1 })
} catch (e) {
console.log(e)
return NextResponse.json({ code: 0 })
}
}
In the code above, you create a POST API endpoint to accept jobs as JSON data. The data is then inserted in your MongoDB database. Afterwards, all the documents stored in the documents array are inserted into the MongoDB vector search index. Under the hood, the vector embeddings for each document is generated using its text property.
Seed the job database
To be able to perform vector search using MongoDB Atlas Search, you need to have at least a single record in a MongoDB database. Hence, an endpoint was created first that you can use to populate your MongoDB database. Use the following command to populate your database via the API endpoint:
curl --location 'http://localhost:3000/api/train' \
--header 'Content-Type: application/json' \
--data '{
"jobs": [
{
"job_title": "Director of Engineer",
"job_description": "Develop, drive and execute a long-term vision and strategy for the payments platform and user economy. Launch cutting edge systems and evolve them to always be performant, reliable, timely and relevant for users.",
"job_link": "https://boards.greenhouse.io/reddit/jobs/5863007"
}
]
}'
Now, let's move on to creating your own MongoDB Atlas vector search instance.
Set up MongoDB Atlas vector search
Navigate to your database cluster in the MongoDB dashboard. Click on the Atlas Search tab. Next, click Create Search Index to start creating the vector index.
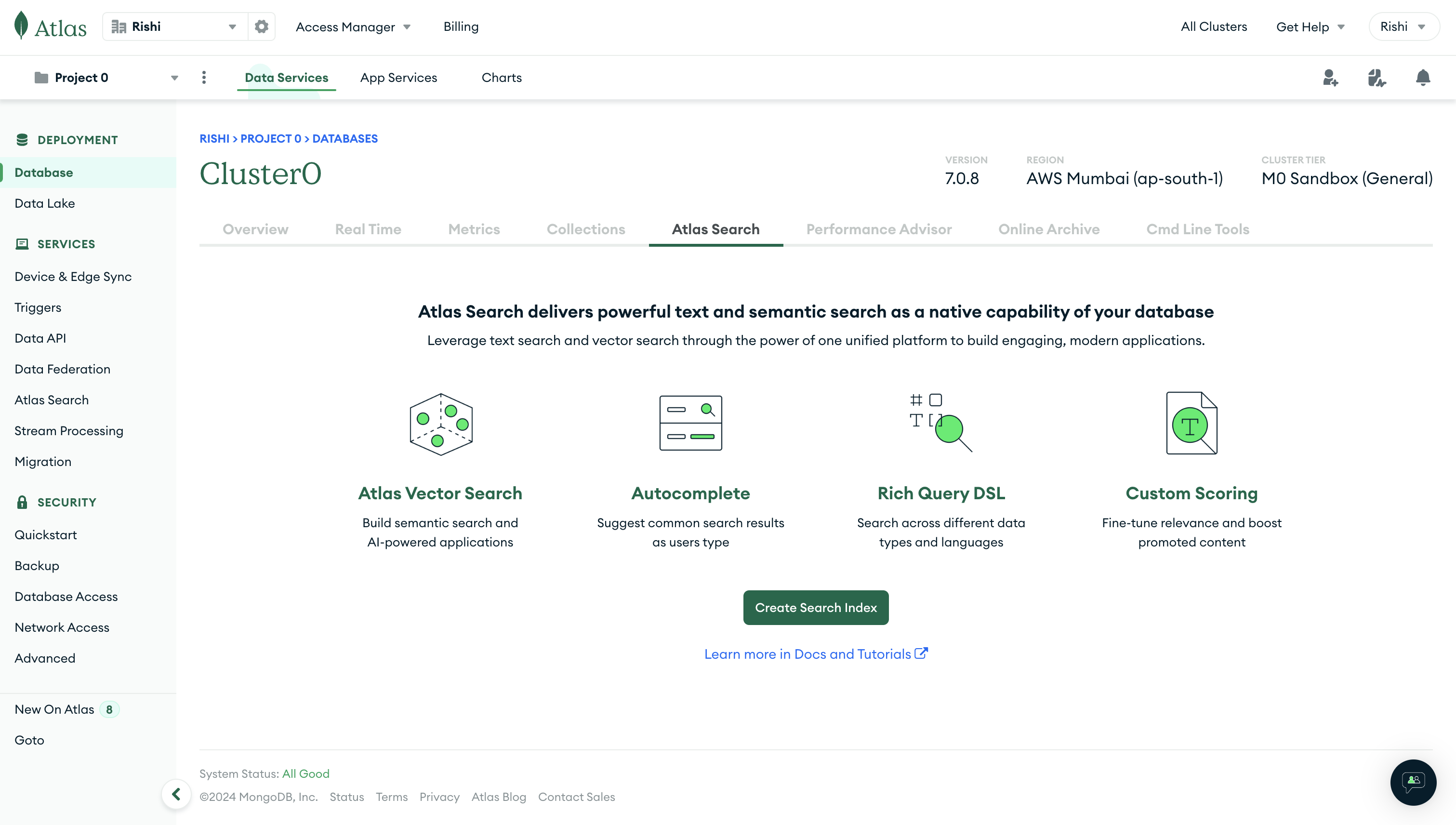
Select the JSON Editor method under the Atlas Vector Search section:
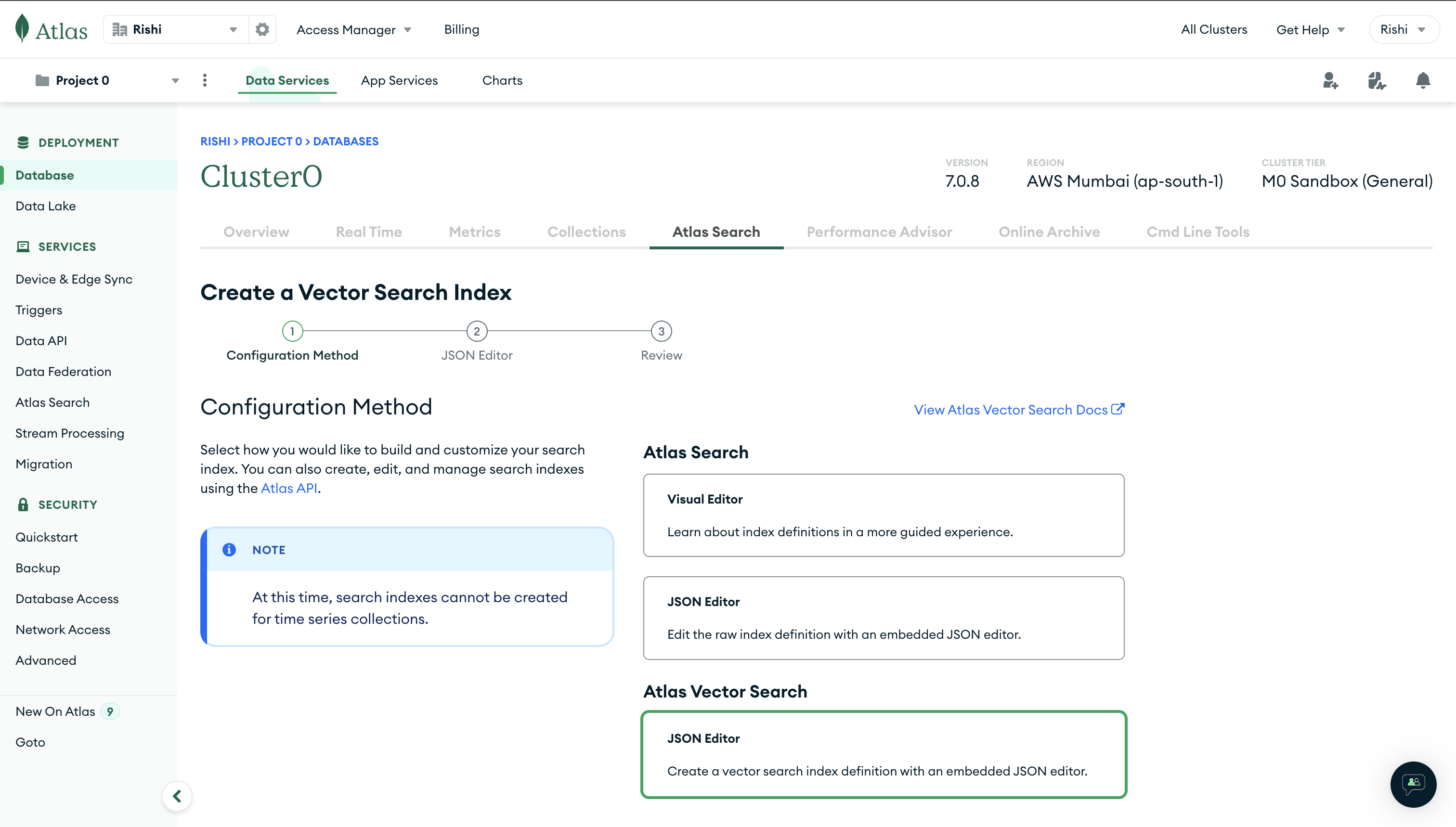
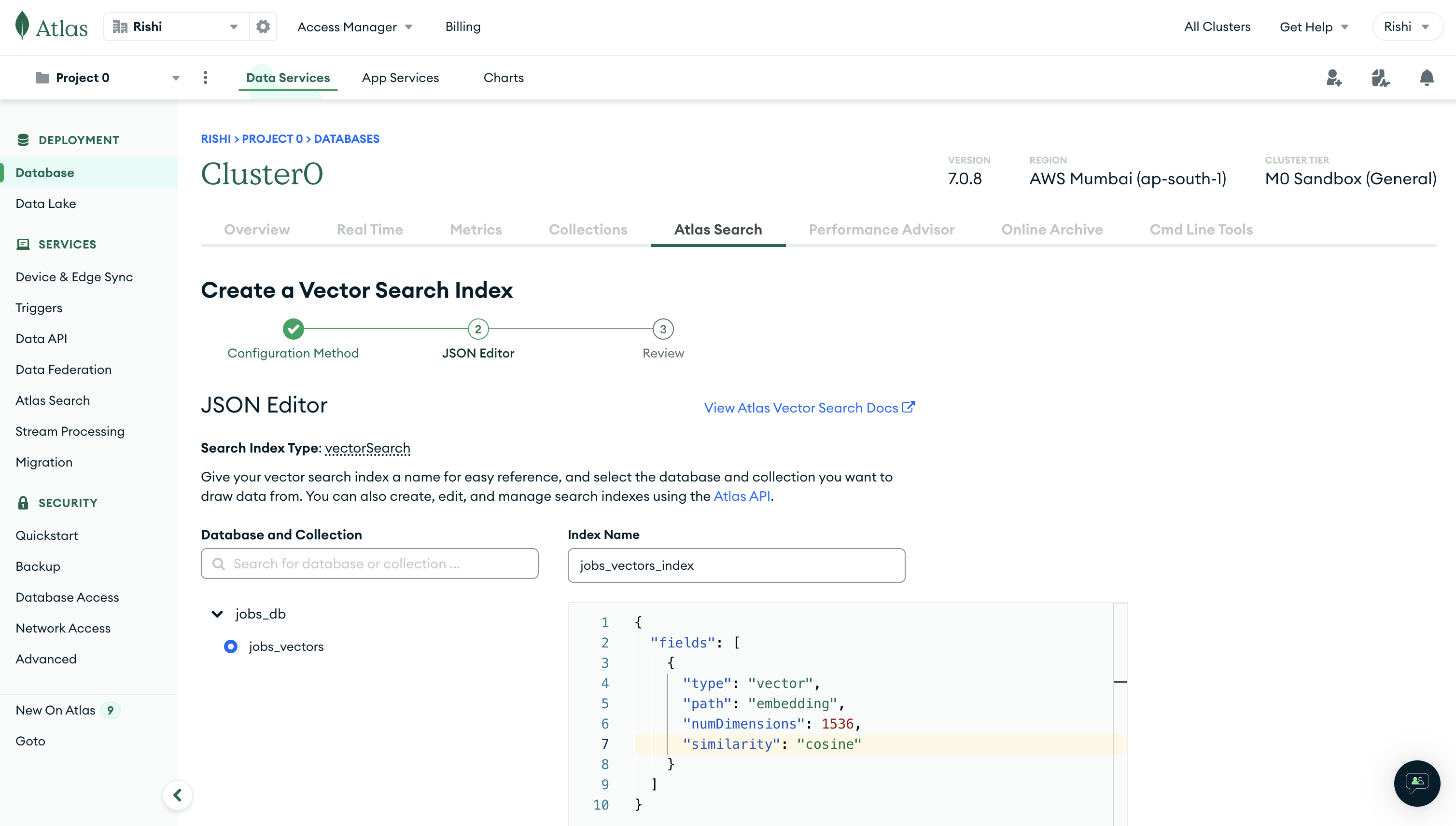
On the following page, select jobs_vectors collection in the jobs_db database to index job data.
Rename the Index Name to jobs_vectors_index (remember to update the value in the .env.local file if you choose to use a different index name) and edit the JSON to be the following:
{
"fields": [
{
"type": "vector",
"path": "embedding",
"numDimensions": 1536,
"similarity": "cosine"
}
]
}
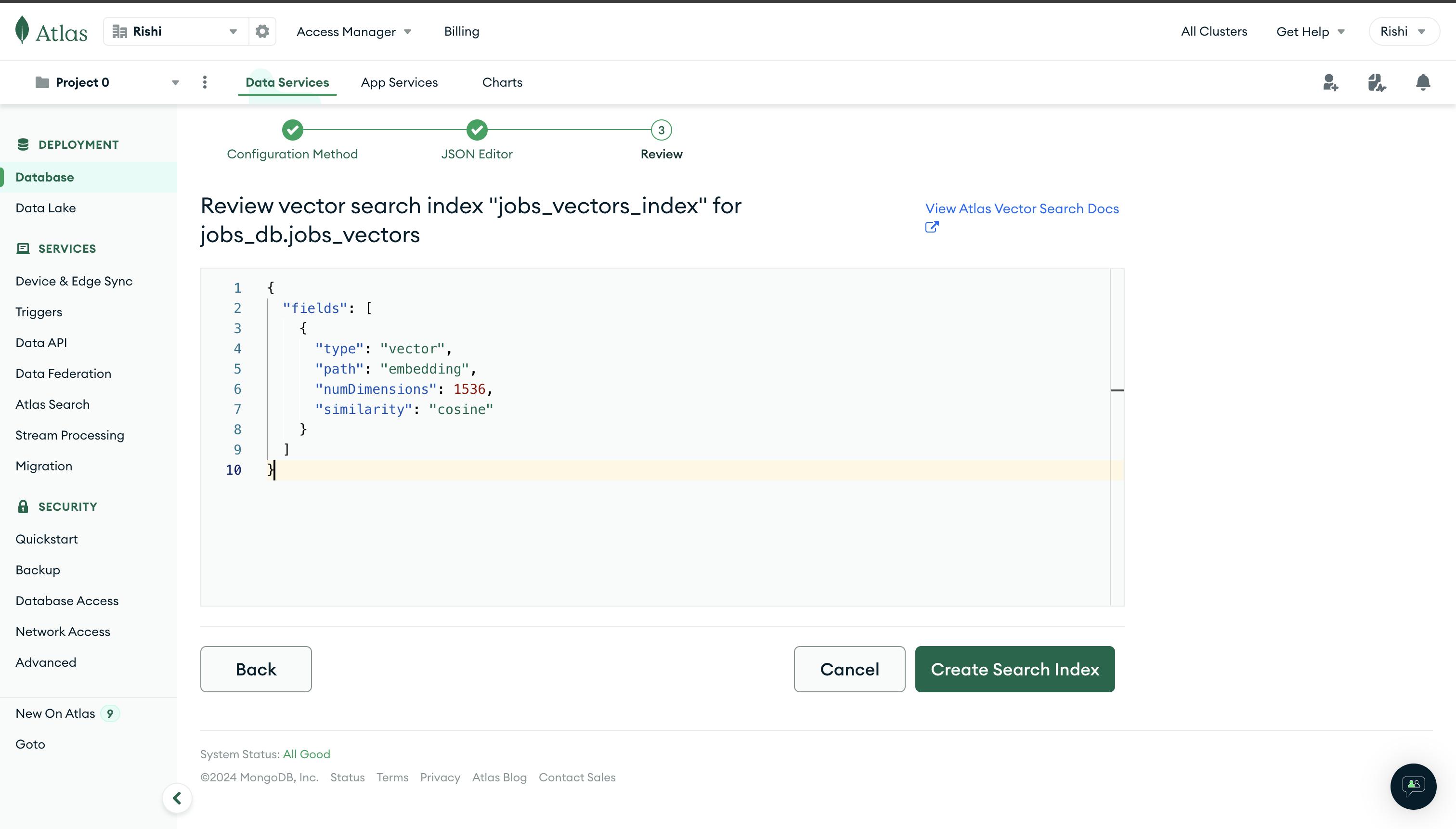
On the next page, click on Create Search Index button to finalize indexing:
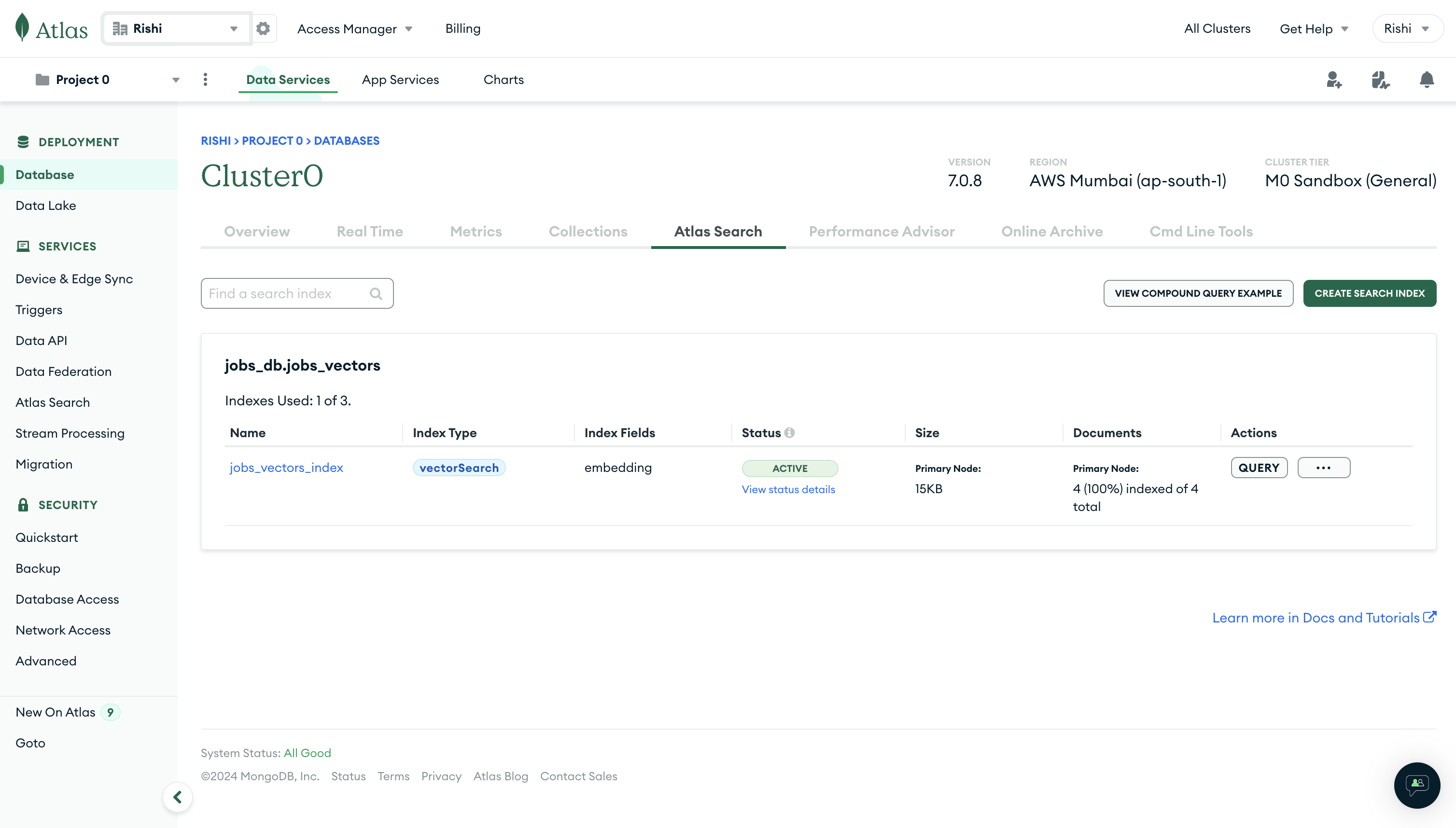
After a few seconds, you should see the status turn into Active after which you can start querying for relevant vectors along with their job metadata:
Now, let's move on to creating the chat user interface for the users to interact with.
Building the index route as the chatbot interface
Open the app/page.tsx file and replace the existing code with the following:
// File: app/page.tsx
"use client";
import { useChat } from "ai/react";
import Markdown from "@/components/markdown";
import { Input } from "@/components/ui/input";
export default function Home() {
const { messages, input, handleInputChange, handleSubmit } = useChat();
return (
<div className="mt-8 gap-y-4 px-4 md:px-0 w-full flex flex-col items-center">
<h1 className="w-[300px] md:w-[600px] text-xl font-semibold">
Job Assistant
</h1>
<form
onSubmit={handleSubmit}
className="border-t pt-8 mt-4 w-[300px] md:w-[600px] flex flex-col"
>
<Input
id="message"
value={input}
type="message"
autoComplete="off"
onChange={handleInputChange}
placeholder="What kind of role are you looking for?"
className="border-black/25 hover:border-black placeholder:text-black/75 rounded-sm"
/>
<button
type="submit"
className="rounded max-w-max mt-2 px-3 py-1 border text-black hover:border-black"
>
Search →
</button>
</form>
<div className="w-[300px] md:w-[600px] flex flex-col">
{messages.map((i, _) => (
<Markdown message={i.content} index={_} />
))}
</div>
<div className="mt-8 w-full"> </div>
</div>
);
}
The code above begins by importing the useChat hook from ai package, the markdown component that you have created earlier to render each message with it, and the input element from the shadcn/ui. In the React component on the homepage, you will deconstruct the following with the useChat hook:
- The reactive
messagesarray which contains the conversation between the user and AI. - The reactive
inputvalue inserted by user into the input field. - The
handleInputChangemethod to make sure theinputvalue is in sync with the changes. - The
handleSubmitmethod to call the API (/api/chat) to get a response for the user’s latest message.
Next, we'll move on to create the chat endpoint that contains references to jobs (including descriptions) related to the user query.
Create a chat API endpoint
Find relevant jobs using MongoDB Atlas vector search
A full text search, or searching through the entire job data stored in your database, is an expensive operation, both in terms of time taken as well as the relevance to the user query. To find relevant jobs easier and faster, you can use vector search for the same. It involves querying the existing set of vectors in your MongoDB Atlas instance. Furthermore, you can filter the vectors whose embeddings carry at least 90% similarity score to the vector embeddings of the user search.
Begin by creating the app/api/chat directory:
mkdir app/api/chat
Inside, create a file called route.ts to handle the POST request created by useChat hook in our React component, with the aim to obtain a response from AI.
// File: app/api/chat/route.ts
export const runtime = "nodejs";
import { VectorStoreIndex } from "llamaindex";
import vectorStore from "@/lib/mongo/store.server";
import { NextRequest, NextResponse } from "next/server";
export async function POST(request: NextRequest) {
try {
const { messages } = await request.json();
const userMessages = messages.filter((i: Message) => i.role === "user");
const query = userMessages[userMessages.length - 1].content;
const index = await VectorStoreIndex.fromVectorStore(vectorStore);
const retriever = index.asRetriever({ similarityTopK: 10 });
const queryEngine = index.asQueryEngine({ retriever });
const { sourceNodes } = await queryEngine.query({ query });
let systemKnowledge: any[] = [];
if (sourceNodes) {
systemKnowledge = sourceNodes
.filter((match) => match.score && match.score > 0.9)
.map((match) => JSON.stringify(match.node.metadata));
}
In the code above, you create a POST API endpoint to accept the conversation between user and AI (i.e. messages) as JSON data. It then filters out user messages and extracts the last user message as a query. Afterwards, it creates a query engine from the index to fetch up to 10 highly relevant documents.
Next, it filters the results based on their similarity score, keeping those with a score greater than 0.9, indicating a high relevance. Finally, it creates an array with metadata of each highly relevant job to create a knowledge base for the chatbot.
Create system context and instructions for OpenAI
Next, we need to instantiate an OpenAI instance to create chat completion responses. The SDK will call the OpenAI chat completion API under the hood.
Create a file named openai.server.ts in the lib directory with the following code:
// File: lib/openai.server.ts
import OpenAI from 'openai'
// Instantiate class to generate text completion using the OpenAI API
export default new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
At this point, you have created a knowledge base for chat with jobs data relevant to the user's query. It's now time to prompt the OpenAI chat completion model to enhance the AI response by inserting it as part of the system knowledge. You will want to get the response to the user from AI as soon as possible, so you will enable streaming using OpenAIStream exported by ai package.
To do implement of this, insert the following code in the app/api/chat/route.ts file:
// File: app/api/chat/route.ts
export const runtime = 'nodejs'
import { VectorStoreIndex } from 'llamaindex'
import completionServer from '@/lib/openai.server' // [!code ++]
import vectorStore from '@/lib/mongo/store.server'
import { NextRequest, NextResponse } from 'next/server'
import { OpenAIStream, StreamingTextResponse, type Message } from 'ai' // [!code ++]
export async function POST(request: NextRequest) {
try {
const { messages } = await request.json()
const userMessages = messages.filter((i: Message) => i.role === 'user')
const query = userMessages[userMessages.length - 1].content
const index = await VectorStoreIndex.fromVectorStore(vectorStore)
const retriever = index.asRetriever({ similarityTopK: 10 })
const queryEngine = index.asQueryEngine({ retriever })
const { sourceNodes } = await queryEngine.query({ query })
let systemKnowledge: any[] = []
if (sourceNodes) {
systemKnowledge = sourceNodes
.filter((match) => match.score && match.score > 0.9)
.map((match) => JSON.stringify(match.node.metadata))
}
const completionResponse = await completionServer.chat.completions.create({ // [!code ++]
stream: true, // [!code ++]
model: 'gpt-3.5-turbo', // [!code ++]
messages: [ // [!code ++]
{ // [!code ++]
// create a system content message to be added as
// the open ai text completion will supply it as the context with the API
role: 'system', // [!code ++]
content: `Behave like a Google for job listings. You have the knowledge of only the following job that are relevant to the user right now: [${JSON.stringify( // [!code ++]
systemKnowledge // [!code ++]
)}]. Each response should be in 100% markdown compatible format, an un-ordered list, have hyperlinks in it to the job taken from the job_link attribute and brief description of what's required in the job taken from the job_description attribute. Be precise.`, // [!code ++]
}, // [!code ++]
// also, pass the whole conversation!
...messages, // [!code ++]
], // [!code ++]
}) // [!code ++]
// Convert the response into a friendly text-stream
const stream = OpenAIStream(completionResponse) // [!code ++]
// Respond with the stream
return new StreamingTextResponse(stream) // [!code ++]
} catch (e) { // [!code ++]
console.log(e) // [!code ++]
return NextResponse.json( // [!code ++]
'There was an Internal Server Error. Can you try again?', // [!code ++]
{ // [!code ++]
status: 500, // [!code ++]
} // [!code ++]
) // [!code ++]
} // [!code ++]
} // [!code ++]
The additions above prompt the Chat completion model using the chat.completions.create function. Each item being passed to the prompt function contains a "role" key which, in our case, can be:
systemrepresenting the system knowledge.userrepresenting the user message.assistantrepresenting the responses from the model.
To make sure that the chatbot responds in only the expected manner, the following is used in the content field to instruct that:
- The chatbot should behave like Google for job listings.
- The chatbot should make sure that the response is in markdown format.
- The chatbot's response should have hyperlinks to the jobs.
- The chatbot goes beyond just including references to the jobs.
- The chatbot should be precise.
You have successfully created a chat endpoint that uses Retrieval Augmented Generation to provide job results closely tied to the user to the chatbot.
Now, let's deploy the application online on the Koyeb platform.
Deploy the Next.js application to Koyeb
Koyeb is a developer-friendly serverless platform to deploy apps globally. No-ops, servers, or infrastructure management is required. It supports many different tech stacks including Rust, Golang, Python, PHP, Node.js, Ruby, and Docker.
With the app now complete, the final step is to deploy it online on Koyeb.
You will use git-driven deployment to deploy on Koyeb. To do this, you need to create a new GitHub repository using the GitHub web interface or the GitHub CLI with the following command:
gh repo create <YOUR_GITHUB_REPOSITORY> --private
Next.js automatically created a git repository with a relevant .gitignore file when we initialized our new project. Add the new GitHub repository as a remote by typing:
git remote add origin git@github.com:<YOUR_GITHUB_USERNAME>/<YOUR_GITHUB_REPOSITORY>.git
git branch -M main
Next, add all the files in your project directory to the git repository and push them to GitHub by typing:
git add .
git commit -m "Initial commit"
git push -u origin main
To deploy the code on the GitHub repository, visit the Koyeb control panel, and while on the Overview tab, click the Create Web Service button to start the deployment process. On the App deployment page:
- Select the GitHub deployment option.
- Choose the GitHub repository for your code from the repository drop down menu. Alternatively, you can enter the example repo for this tutorial in the Public GitHub repository field:
https://github.com/koyeb/example-llamaindex-mongodb-job-search. - In the Environment variables and files section, click Bulk edit. Paste the variables defined in your
.env.localfile and click Save. - Enter a name for the application or use the provided one.
- Finally, initiate the deployment process by selecting the Deploy button.
During the deployment on Koyeb, the process identifies the build and start scripts outlined in the package.json file, using them to build and launch the application. You can follow the deployment progress through the displayed logs. Upon the completion of deployment and the successful execution of vital health checks, your application will be operational.
Conclusion
In this tutorial, you created a job assistant application with Next.js using MongoDB Atlas vector search and the OpenAI chat completion API. During the process, you learned how to perform vector search with LlamaIndex on a MongoDB database to find relevant jobs for the user. You also used the OpenAI API to create markdown compatible responses containing a brief description with a link to job role(s).
Given that the application was deployed with the git deployment option, subsequent code pushes to the deployed branch will automatically initiate a new build for your application. Changes to your application will become live once the deployment is successful. In the event of a failed deployment, Koyeb retains the last operational production deployment, ensuring the uninterrupted operation of your application.

