December Recap: Scale-to-Zero, Serverless GPU Price Drop, and more
This December has been full of pivotal serverless milestones. We've rolled out a series of major features designed to make your deployments experience smoother, faster, and more cost-effective:
- Scale-to-Zero: Automatically scale your infrastructure down to zero when your Service has no traffic.
- Serverless GPU Price Drop: Access high-performance serverless GPUs at a lower cost. Combine with Scale-to-Zero and autoscaling for optimal efficiency.
- AI Models in One-Click Catalog: Deploy open-source AI models with a single click. Get a dedicated endpoint in seconds with zero-configuration.
- New Plans: Pro and Scale: For managing fleets of Services and scaling effortlessly.
Let’s dive into this recap to cover everything that is new and share the resources you need to run and scale your workloads.
Introducing Scale-to-Zero: Efficiency Perfected
Why pay for idle resources? With Scale-to-Zero, you’ll only pay for what you use. This feature automatically scales your infrastructure down to zero when your Service has no traffic and its underlying Instance is not in use, ultimately ensuring that your costs are optimized.
Whether handling bursts of traffic or performing real-time inference, Scale-to-Zero ensures you’re never spending a penny more than necessary. Combine it with autoscaling to handle all of your fluctuations in traffic.
What’s in it for you?
- Unparalleled Cost Savings: You only pay for what you use. When there’s no traffic, your instances scale to zero, so you're not wasting money.
- Smarter Resource Use: Focus on developing without worrying about over-provisioned infrastructure.
- Instant Readiness: Your workloads spin up when new requests come in. Perfect for workloads with unpredictable demand.
Price Drops: Serverless GPUs Are More Affordable
Accessing high-performance serverless GPUs is now easier than ever, thanks to our price drops on L4, L40S, and A100.
We’re committed to simplifying AI development, and this move alongside the release of Scale-to-Zero makes cutting-edge compute power accessible to all teams, from startups to enterprises.

How this helps you:
- More compute for less: Combine Scale-to-Zero, Autoscaling, and better prices for huge improvements in efficiency.
- Prototype and test more: Scale experiments without financial constraints.
- High-performance GPUs charged per second: Deploy production-grade models without compromising on performance or scale.
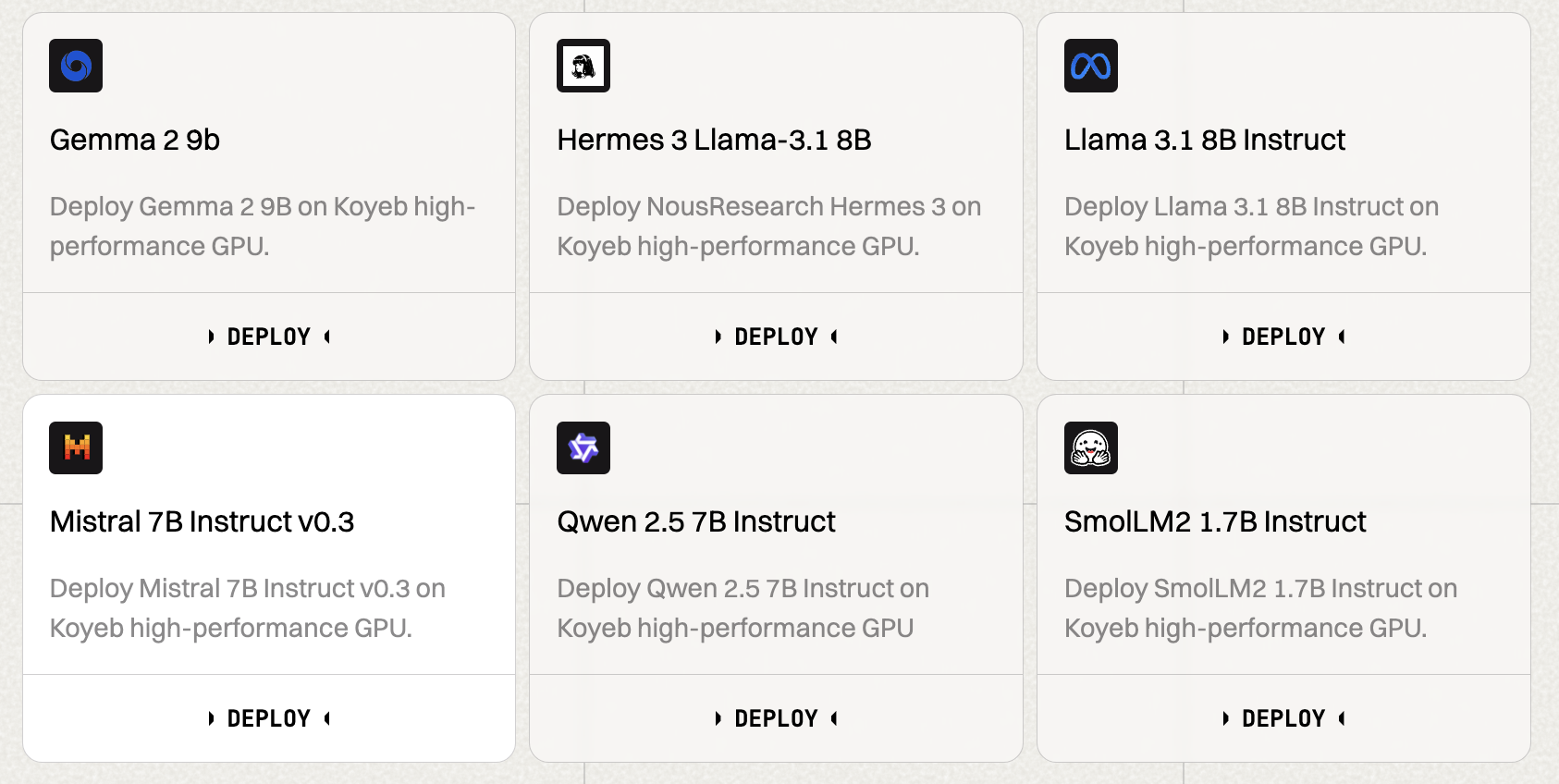
AI Models Available in Our One-Click Catalog
Getting started with the best AI open source models just got simpler. Our One-Click Catalog now features six pre-built AI models ready for deployment:
- Gemma 2 9b
- Llama 3.1 8B Instruct
- Hermes 3 Llama 3.1 8B
- Mistral 7B Instruct v0.3
- Qwen 2.5 7B Instruct
- SmolLM2 1.7B Instruct
With these one-click deployments, you get a dedicated endpoint ready to handle inference requests in seconds. With zero-configuration, automatically scale your infrastructure based on real-time traffic and scale down to zero during idle periods.
Key benefits:
- Dedicated enpoint in seconds: Start building immediately with ready-to-use models.
- Faster deployments: Experiment faster, iterate smarter.
- Zero-configuration high-performance infrastructure: Skip complex setup steps and focus on your solution.
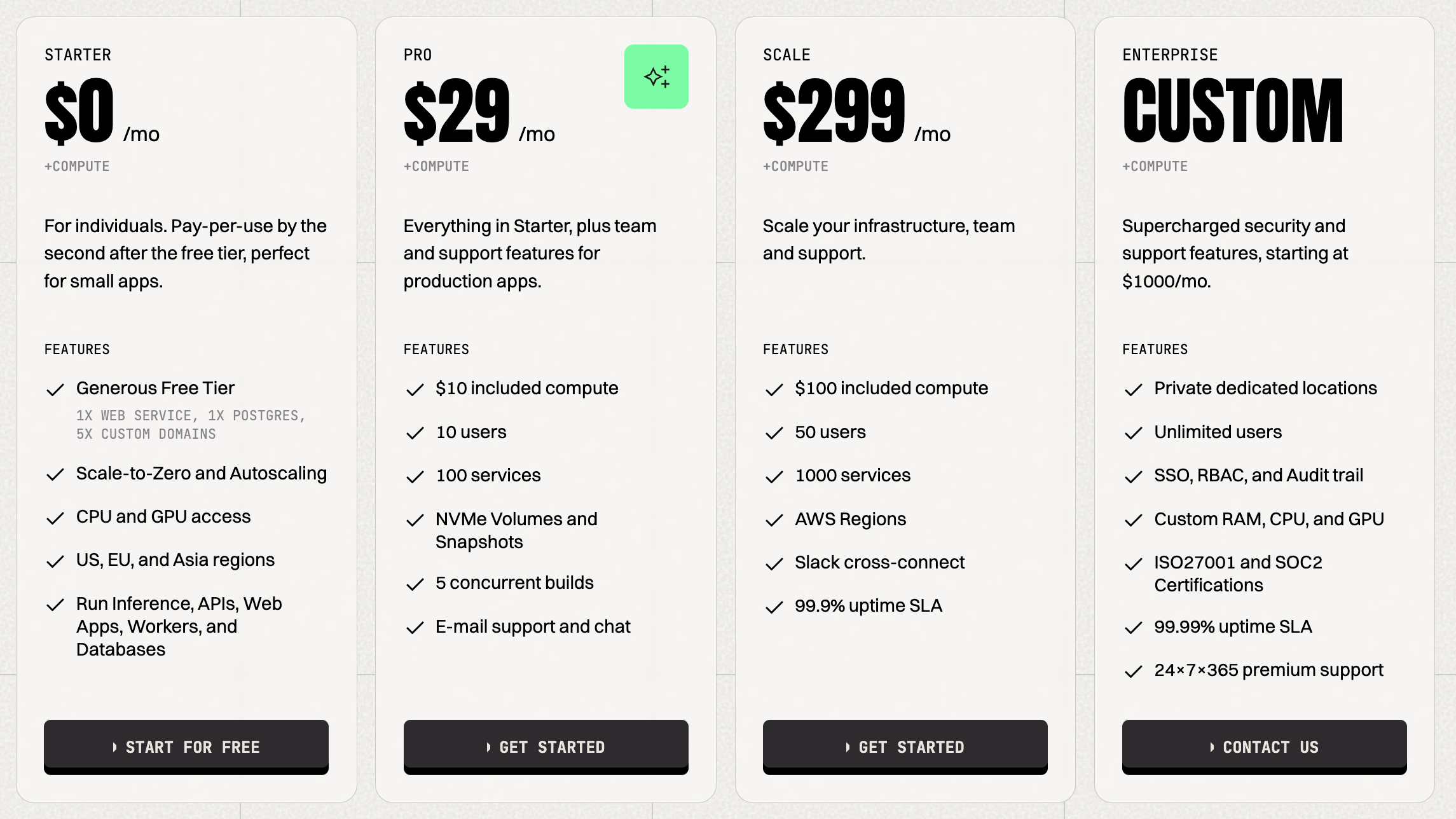
New Plans: Pro and Scale for Every Need
We introduced two new plans to help you manage fleets of Services and scale effortlessly:
- Pro Plan: Perfect for professional teams that require reliable, high-performance infrastructure. This plan ensures you have the resources you need to build and scale as you need.
- Scale Plan: Designed for scaling companies managing complex workloads, the Scale Plan offers unmatched flexibility, scalability, and performance to support your most resource-intensive projects.
Why it matters:
- Choose the plan that fits your stage of growth.
- Tailored features and pricing.
- Scale effortlessly as your needs evolve.
What’s next? Let’s build together!
These updates are about giving you access to the high-performance infrastructure your workloads need to run and scale in production:
- Better Performance: Access cutting-edge GPUs that automatically scale for maximum efficiency.
- Lower Costs: Pay only for what you use, and benefit from reduced GPU pricing.
- More Simplicity: From autoscaling and scale-to-zero, to the one-click catalog, we’re all about removing friction from your workflow.
On top of all this, we also released a new website. More than just a revamp, it reflects our commitment provide high-performance infrastructure for AI apps, full-stack apps, inference, APIs, and everything you're deploying to production.
Your feedback drives us. Let us know what features you want to see on the platform with our feature request platform.
There are updates coming ahead in 2025! Check out our public roadmap and stay tuned! Until then, we’re excited to see how you’ll leverage these latest updates to build and scale your applications.
By the way, if you really want to build with us - we’re hiring! Check out our open positions and reach out if you’d like to help us build the serverless future!