Autoscaling GA: Scale Fast, Sleep Well, Don't Break the Bank
We are thrilled to kickstart this first launch week with autoscaling - now generally available!
Our goal is to offer a global and serverless experience for your deployments. Autoscaling makes this vision a reality. Say goodbye to overpaying for unused resources and late-night alerts for unhealthy instances or underprovisioned resources!
During the autoscaling public preview, we received key feedback around scaling factors. As part of this GA release, we are adding the possibility to scale based on the number of concurrent connections and p95 response time.
Autoscaling now works across Standard and GPU-based Instances.
Read on below to learn how you can start autoscaling your services today using advanced criteria adapted to your apps.
Setting up Autoscaling
Configuring autoscaling on the platform is dead simple: it's a slider and a checkbox (or 3 arguments with the CLI). The question when you deploy is: when to scale up and down? What are the metrics that accurately represent the load of my application?
In our initial release, we enabled autoscaling on up to three metrics to precisely respond to workload changes:
- Requests per second: The number of new requests per second per Instance.
- CPU: The CPU usage per Instance.
- Memory: The memory usage per Instance.
The feedback we got was that response time and concurrent requests would be useful to adjust the number of Instances. So, we added two criteria:
- P95 response time: Your service's 95th percentile response time. You can view your service's p95 response time in its Metrics.
- Concurrent connections: The number of active connections per Instance.
How autoscaling works on the platform
Autoscaling checks your deployment every 15 seconds to decide if it needs to scale. To avoid rapid changes and maintain stability, once a scaling action is taken, a 1-minute window starts. During this time, no further actions will occur.
When multiple scaling criteria are configured, we calculate the minimum number of Instances required to remain below the target value for each metric. Your Instances are always scaled according to the range you specify.
All autoscaling decisions are taken based on an average of all Instances of a Service on a per-region basis. A spike in Singapore will not affect San Francisco.
If you want to read more about how autoscaling works on the platform, check out our autoscaling engineering blog post:
Learn how we implemented autoscaling into our platform for global and serverless deployments.
Defining the Right Autoscaling Policy for Your Services
To help you define and tune your Autoscaling policy, we natively provide a set of metrics to monitor your service and its performance: CPU, memory, response time, request throughput, and public data transfer.
You can use these metrics as a starting point to define your first autoscaling policies. Based on your observations, configure your Autoscaling policy according to how your application needs to scale.

Predictable Pricing
Autoscaling is billed like other resources on the platform: you are charged based on the number of Instances you use across all regions where your service is deployed and the time the Instances are running, per second of usage.
When you configure your applications and services for deployment on the platform, we automatically calculate the maximum cost of your deployment based on the maximum number of Instances you set for your Service across the regions selected.
Example: Autoscaling a Service running on a large Instance across 3 regions
If your service needs the resources of a large Instance and you deploy it across 3 regions with autoscaling set to 1 to 3 Instances per region, the platform will calculate the maximum cost of your deployment based on the maximum number of Instances you set for your Service across the regions selected.
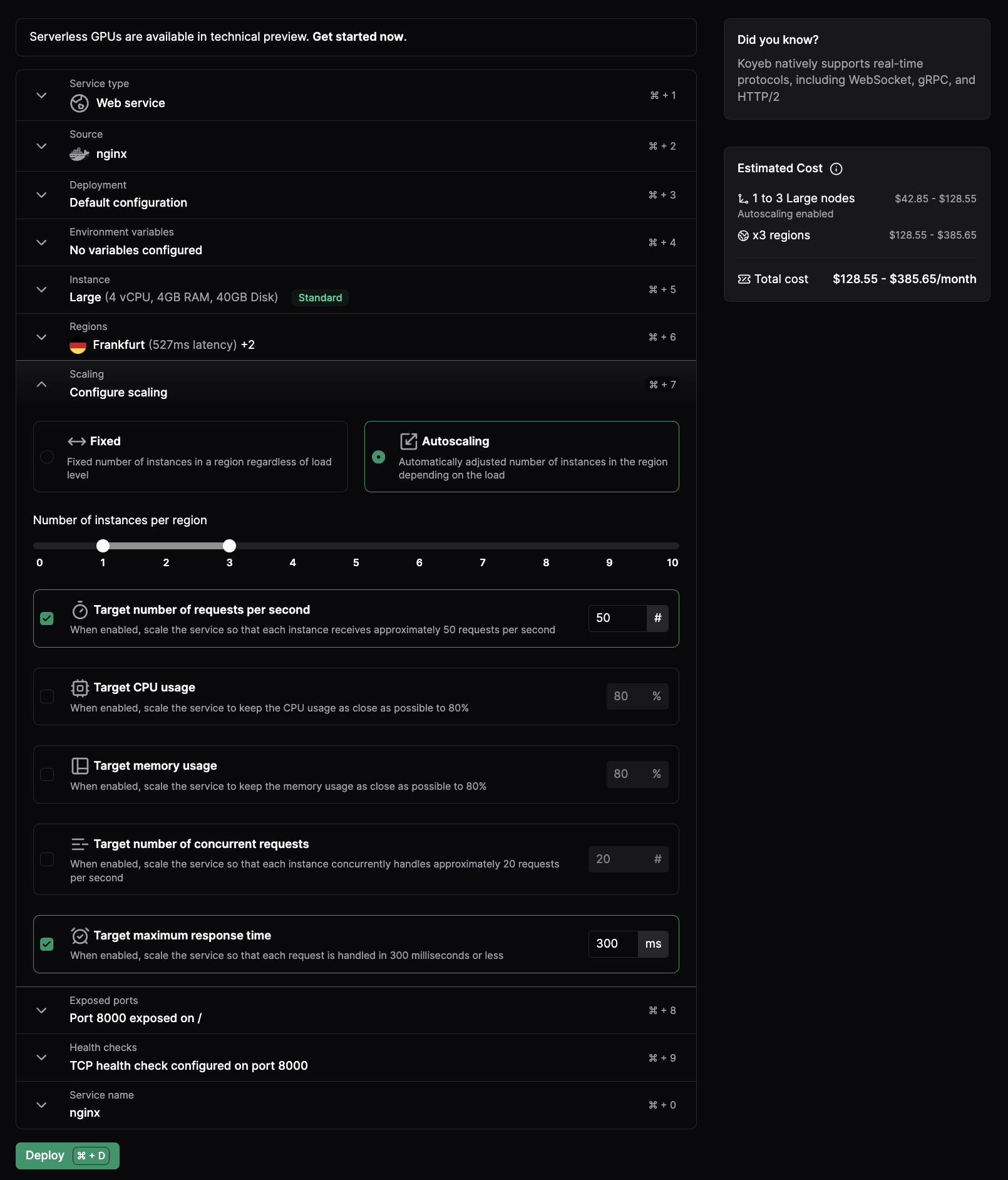
In this example, it will cost between $128 and $385 to run this service with 3 large Instances across 3 regions with autoscaling set to 1 to 3 Instances per region. At the end of the month, you only pay for the resources your service uses depending on the load and the time they are running.
Check out our pricing page and Pricing FAQ for detailed information on the cost of Instances.
Autoscaling GA is part of 5 days of amazing releases
Getting Started with Autoscaling
Enabling Autoscaling on your Services is just a CLI command or a one-click action via the control panel.
Autoscaling with the CLI
koyeb app init sky \
--docker koyeb/demo \
--autoscaling-concurrent-requests 20 \
--min-scale 2 \
--max-scale 10 \
--regions fra,was,sin
The command above will deploy a new Service named sky in Frankfurt, Washington, D.C., and Singapore with a minimum of 2 and a maximum of 10 Instances.
The autoscaling policy is set to scale up when the average number of concurrent requests is above 20 per Instance.
Autoscaling with multiple policies
Adding a new scaling policy can easily be performed by updating the service configuration. We can add a new policy to scale up when the service P95 is above 300ms.
koyeb service update sky/sky --autoscaling-requests-response-time 300
The Service will now automatically scale up and down according to concurrent connections and P95 response time.
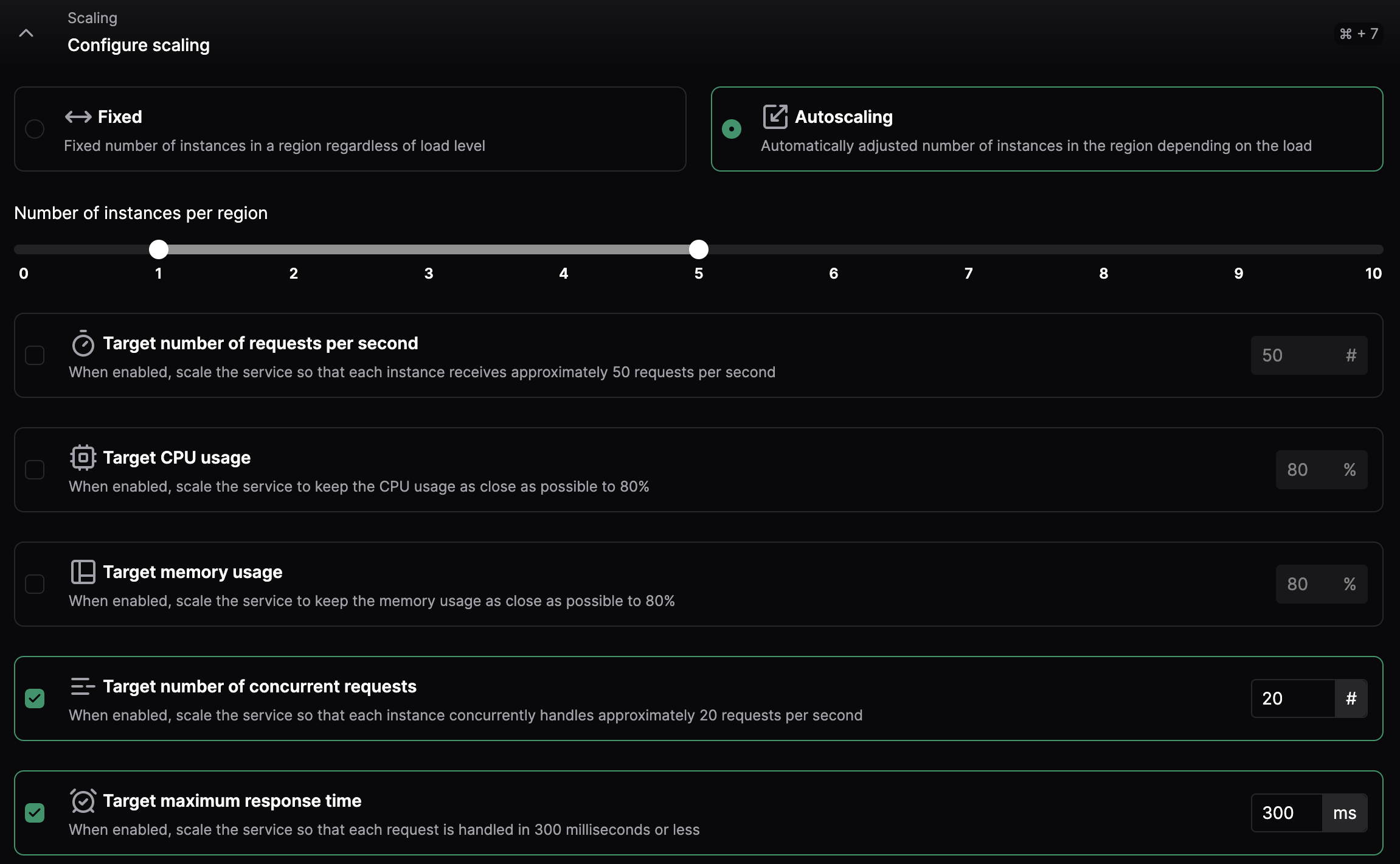
Autoscaling with the Control Panel
You can also enable Autoscaling directly from the control panel. From your Service's configuration page, you can set the Autoscaling policies for the range of minimum and maximum Instances for your service based on target requests per second, CPU usage, memory usage, concurrent requests, and P95 response time.
What’s next?
Autoscaling is one of the most important features we've released this year. It's no secret why: it seems nobody likes to manually adjust the number of instances when there is a sudden spike of traffic in the middle of the night.
Managing unpredictable spikes and varying workloads is essential for the success of your services and businesses. Fine-tuning this feature was a team effort, and we are thrilled to share it with you and your applications.
We're looking forward to seeing how you'll use it to power and scale your applications.
-
New to Koyeb? To get started with the platform, you can sign up today and start deploying your first Service today.
-
If you want to dive deeper into autoscaling, have a look at the documentation.
Happy autoscaling! 🚀
Keep up with all the latest updates by joining our vibrant and friendly serverless community or follow us on X at @gokoyeb.