The engineering behind autoscaling with HashiCorp's Nomad on a global serverless platform
There are several ways to handle load spikes on a service.
- One of the most common ways is to scale vertically, by selecting a bigger instance to handle peak loads.
- Another way is to always have enough smaller instances running to handle the load. This is called manual horizontal scaling.
However, these methods are not cost-effective: you either pay for resources you don't use, or you risk not having enough resources to handle the load.
Fortunately, there is a third way: horizontal autoscaling. Horizontal autoscaling is the process of dynamically adjusting the number of instances of a service based on the current load. This way, you only pay for the resources you use, and you can handle load spikes without any manual intervention.
Our Infrastructure Requirements
As a cloud platform, we run our users' services inside Instances. Instances are the runtime units that execute a project's code. When an application is deployed on the platform, the code is built and packaged into a container image and run as an Instance. Under the hood, Instances are Firecracker microVMs, which are running on bare metal servers.
Autoscaling requires us to answer several questions regarding infrastructure:
- How do we scale up or down a service?
- When do we scale up or down a service?
- How long does it take to spin up a new instance?
- How do we spread the load across the scaled Instances?
- How do we prevent abrupt scaling changes, especially when scaling down?
How autoscaling works from a user's perspective
We already covered the basics of autoscaling in the public preview announcement. To recap, on our platform, three criteria are used to determine if an application should be scaled up or down: the number of requests, the memory usage, and the CPU usage. As a user, you define a target for at least one of these criteria, and the autoscaler will scale up or down the application to keep the usage as close as possible to the target. These criteria must be configured per region, so you can have different autoscaling policies in different regions.
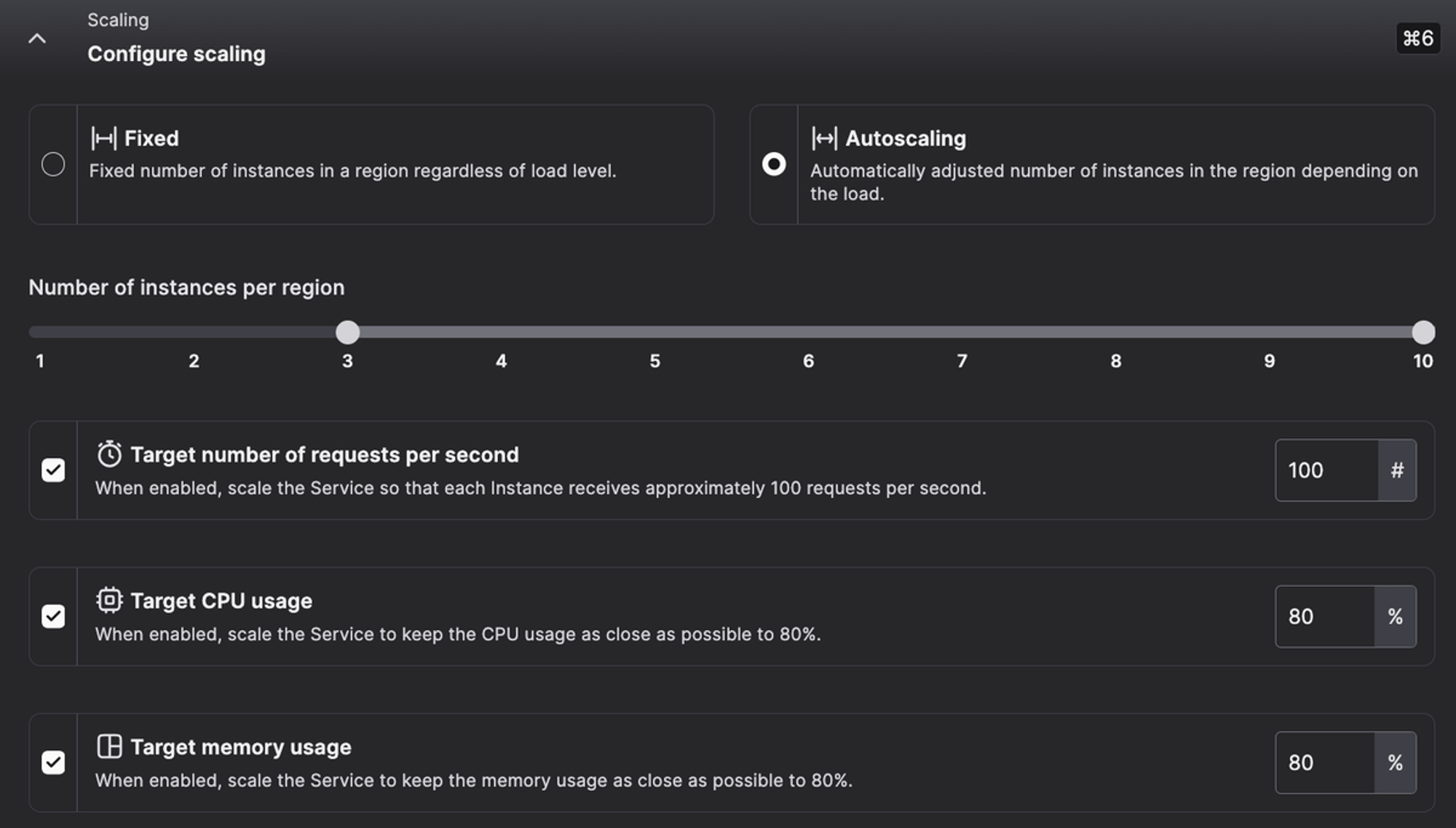
How do we scale up or down a service? Nomad Autoscaler!
If you are a long-time reader of our blog, you already know that we use Nomad to run services on our platform. Behind the scenes, each of our regions is a separate Nomad cluster composed of several nodes.
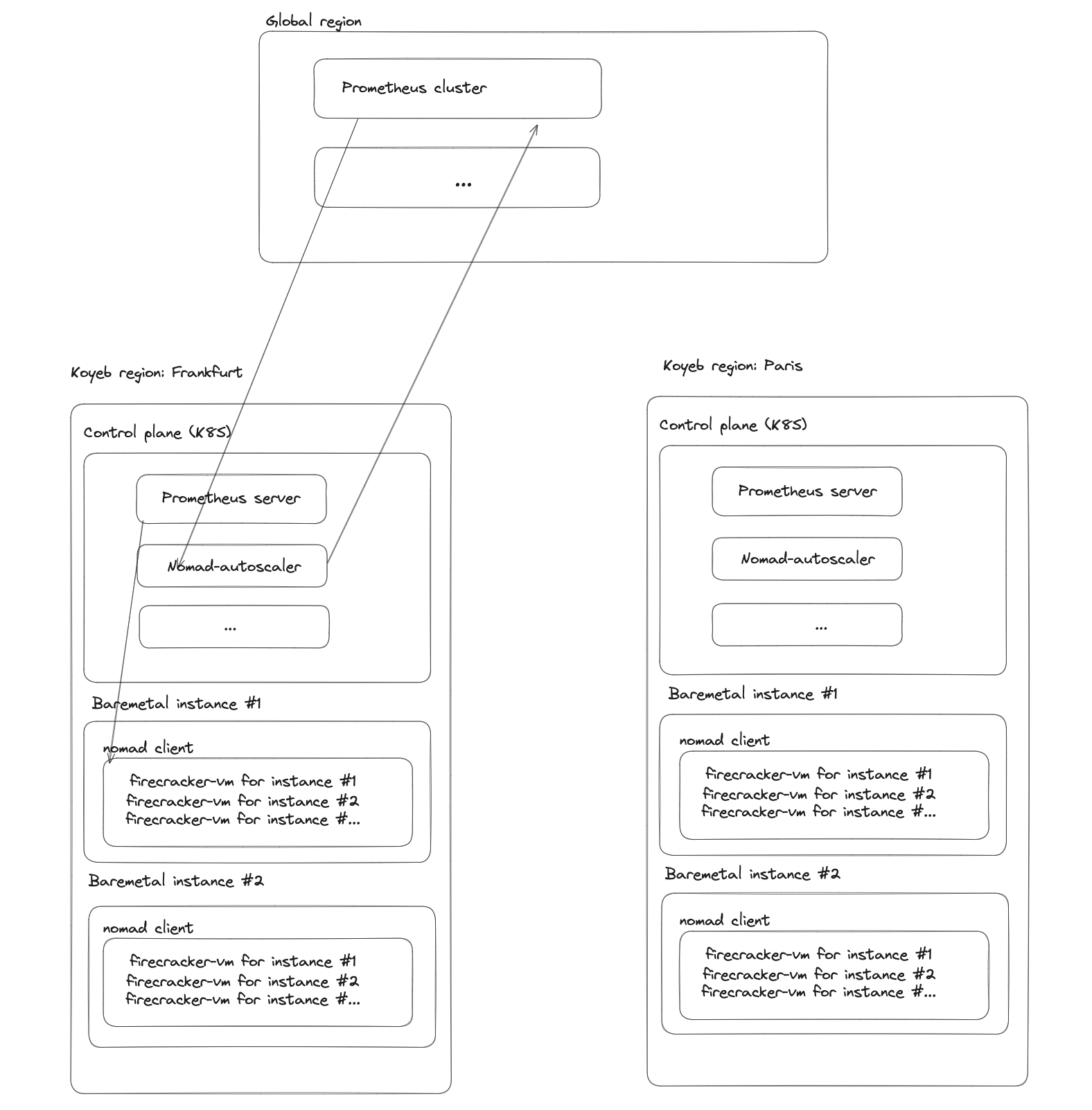
When you start a new service on Frankfurt, for example, our control plane does nothing more than sending a gRPC request to the Nomad cluster in Frankfurt. The Nomad cluster then starts the service on one of its nodes.
😂 "Nothing more than sending a gRPC request": lol Koyeb is so simple.
Ok, we admit, it's not that simple. We also need to start firecracker microVM to isolate your service from the other services running on the same node, manage the load balancing bringing the traffic to your services, maintain the vault cluster to store your secrets, and the monitoring stack to collect metrics and logs. We obviously also need to maintain the API used by our control panel and the CLI. All of this goes without talking about keeping the system up-to-date, secure, and reliable.
Anyway, it's not the point of this article. Let's get back to autoscaling!
To scale up or down a service, we use Nomad Autoscaler. The Nomad Autoscaler, as its name suggests, is an autoscaling daemon for Nomad.
The Autoscaler's job is to periodically check the jobs running on the cluster, and for each job with a scaling policy defined, check if the job needs to be scaled up or down. Depending on the policy, the autoscaler will increase or decrease the number of instances of the job.
If you have a Nomad cluster running locally, adjusting the number of instances of a job is as simple as running nomad job scale <job_name> <instances_count>, and that's exactly what the autoscaler does.
When do we scale up or down a service? Metrics!
Nomad Autoscaler is architectured around plugins. The APM (for "Application Performance Management") plugin is responsible for collecting the metrics from the job. In production, we use the prometheus plugin which performs a query on a Prometheus server.
The APM plugin expects a query to be defined in the job file, and will periodically run this query to get the metrics.
For example, the Prometheus query we use for CPU autoscaling is:
sum(metrics_server_service_cpu_total_percent{
service_id="<service>", region="<region>"
}) / sum(metrics_server_service_cpu_allocated{
service_id="<service>", region="<region>"
}) * 100
This query divides the total CPU usage by the total CPU allocated for the service, and returns the result as a percentage. For example, if your service is running on a medium instance (with 2 vCPUS) and is using 100% of a vCPU, and 20% of the other, the result of this query will be (100 + 20) / 200 * 100 = 60%.
From the value returned by the query, the autoscaler needs to decide if the service should be scaled up or down. To do this, the autoscaler is using a strategy. Among the strategies Nomad Autoscaler provides, we use two of them:
- target-value: with this strategy, the autoscaler will scale the service up or down to keep the value as close as possible to a target value. For example, if you set the target value to 80%, the autoscaler will scale up the service if the value is below 80%, and scale down the service if the value is above 80%. We use this strategy for the CPU and memory usage.
- passthrough: with this strategy, the autoscaler will scale the service up or down based on the value returned by the query. This strategy expects the query to return the number of instances the service should have. We use this strategy to scale based on the number of HTTP requests.
How long does it take to spin up a new instance?
When you autoscale a service on our platform, a new Instance running your service is spun up as soon as one of the target thresholds you configured is hit. We do not need to rebuild your application to automatically scale it it because the image for your application is already built and available in our container registry. All we need to do is pull the container image for your application from the container registry, start it, and configure the load balancing to route traffic between the active Instances. The entire process takes less than a minute and often just a few seconds, depending on the size of your application.
How do we spread the load across the scaled Instances? Kuma!
Using Nomad Autoscaler is great to scale up or down a service, but it doesn't help to spread the load across the instances. To do this, we use Kuma, a service mesh build on top of Envoy.
Kuma is responsible for routing the traffic to the instances of the service. When a new instance is started, Kuma will automatically start sending traffic to it. When an instance is stopped, Kuma will stop sending traffic to it. This way, the load is automatically spread across the instances.
In the context of autoscaling, load balancing traffic across instances is as important as scaling up or down the service. If you scale up a service but do not send traffic to the new instances, or if you scale down a service but do not stop sending traffic to the old instances, the purpose of autoscaling is defeated.
How do we prevent abrupt scaling changes? Cool down policy!
A challenge with autoscaling is to prevent abrupt scaling changes. If your application is running on 10 instances, and the CPU usage suddenly drops from 100% on average to 10%, you probably don't want the autoscaler to scale down to 1 instance immediately. Instead, you want the autoscaler to scale down gradually, to give your service time to adjust to the new load, and make sure you always have enough instances to handle the load.
Nomad Autoscaler has a built-in cooldown period to prevent abrupt scaling changes. After a scale up or down, the autoscaler will wait for a fixed amount of time (about 1 minute) before scaling again. This way, the service has time to adjust to the new number of instances before the autoscaler makes another change.
We also made a pull request to the Nomad Autoscaler to add a new feature: the ability to define a maximum number of instances to scale up or down at once. This way, you can prevent the autoscaler from scaling up or down too quickly. We use this feature to prevent the autoscaler from scaling down more than one instance at a time, to let the service adjust to the new load before scaling down again if needed.
Future improvements for autoscaling on Koyeb
Autoscaling is a complex topic, and we have tons of ideas to make it better. However, we need your feedback to know what to prioritize! If you have use cases that are not covered by our current implementation, or if you have ideas to make it better, let us know on feedback.koyeb.com.
- More metrics! Currently, we only support scaling based on the number of requests, the memory usage, and the CPU usage. We plan to add more metrics in the future, such as the average response time. This will allow you to scale based on the performance of your service, not just its resource usage.
- Autoscaling based on custom metrics: Currently, we only support scaling based on the number of requests, the memory usage, and the CPU usage. Why not scale up or down based on any metrics you want?
- Configurable cooldown period: After a scale up or down, we apply a cooldown period to prevent abrupt scaling changes. Currently, this period is fixed at 1 minute, but we could make it configurable in the future to make your service more or less reactive to load changes, depending on your needs.
- Cron-based autoscaling: Instead of scaling based on the current load, why not scale based on a schedule? This could be useful for services that have predictable load changes, for example, a service that is used only during business hours.
Enjoy autoscaling, automatic continuous deployment, global load balancing, real-time metrics and monitoring, and more.
Conclusion
Autoscaling is a powerful feature that allows you to handle load spikes without any manual intervention. On our platform, we use Nomad Autoscaler. For us, the complexity of autoscaling is not in the autoscaler itself, but in the whole infrastructure that goes around it: the service mesh, the monitoring stack, the load balancer, and so on.
Fortunately, we have all of this in place, so you can focus on building your application, and let us handle the rest.