Using Groq to Build a Real-Time Language Translation App
In today's interconnected world, chatting across different languages is more important than ever. Real-time language translation has become a game-changer, breaking language barriers and making global communication a breeze.
By tapping into the powers of Speech-to-Text (STT) technology, the Groq API for super-fast Large Language Model (LLM) translation, and Text-to-Speech (TTS) systems, we can give language translation a serious makeover.
This article takes a deep dive into a cool mix of these technologies, exploring how they can be combined to bring you smooth, real-time language translation. Whether you're a tech geek, a language lover, or a business eager to go global, this approach to real-time language translation can put you on the right track.
Follow along as we integrate these technologies to create a practical translation application. We'll begin by using speech-to-text to turn spoken words into written text. We'll then feed the text into the Groq API, a cutting-edge tool that uses machine learning to provide super-fast responses based on large language models (LLMs). The translated text will then be turned back into speech with the help of text-to-speech technology, giving you a complete, real-time translation solution.
You can deploy the Groq language translation application as configured in this guide using the Deploy to Koyeb button below:

Note: Be sure to change the value of the GROQ_API_KEY environment variable to your Groq API key when you deploy. You can take a look at the application we will be building in this tutorial in the project GitHub repository.
Requirements
To follow along with this guide, you'll need the following:
- Groq API Key: You need a Groq API key to access the AI translation services.
- Koyeb Account: We will deploy the complete application to Koyeb to take advantage of its integration and deployment features.
- GitHub Account: You'll also need a GitHub account for version control and to manage the project's codebase.
Understanding of the components
Before creating the translation application, let's take a look at the components that it will rely on.
Speech-to-text (STT)
Speech-to-text (STT), also referred to as speech recognition, is a technology that transforms spoken words into written text. It relies on sophisticated algorithms and machine learning models to identify and transcribe human speech, considering various aspects like accent, dialect, and speaking pace.
STT technology is used in a multitude of ways, from voice assistants and dictation tools to real-time translation services. It has made impressive strides in recent years, boasting remarkable enhancements in accuracy and speed, which makes it an indispensable element in various sectors such as healthcare, education, and customer service.
When it comes to real-time language translation, STT serves as the first step, converting spoken language into written text that's then processed by translation models. The precision and swiftness of STT technology have a direct bearing on the overall quality and effectiveness of the translation process.
For our real-time STT needs, we'll employ a fantastic library called faster-whisper.
Groq
Groq is a tech company that is creating high-performance computing solutions with a special focus on artificial intelligence (AI) and machine learning (ML) applications. Renowned for its inventive approach to handling AI workloads with remarkable speed and efficiency, Groq stands out from the crowd. Unlike traditional GPU (Graphics Processing Unit) and CPU (Central Processing Unit) architectures, Groq simplifies hardware design, reducing complexity, and minimizing data movement, a common hurdle in high-performance computing tasks.
Among Groq's notable offerings is its Tensor Streaming Processor (TSP) architecture, engineered to run machine learning models and other computational tasks at impressive speeds. This architecture centers around the idea of deterministic processing, which means it can reliably execute tasks with minimal latency. This makes it particularly suitable for real-time applications, such as autonomous vehicles, financial trading algorithms, and, of course, real-time language translation systems.
In the context of real-time language translation, the Groq API is a valuable tool that harnesses the platform's hardware and software capabilities. It enables developers to tap into large language models for various applications, including translation.
Text-to-speech (TTS)
Text-to-speech (TTS) is a technology that transforms written text into spoken words. It utilizes synthetic voices to read out text, offering an audible version of written content. TTS technology has applications in many areas including voice assistants, audiobooks, and accessibility tools for the visually impaired.
In the context of real-time language translation, TTS represents the final step in the process. Once the spoken language is converted into text using speech-to-text (STT) technology and translated into the target language with the Groq API, the translated text is then converted back into speech via TTS. This results in a comprehensive, real-time translation solution.
Similar to STT, TTS technology has also made considerable progress in recent years. Synthesized voices now sound more natural than ever, enhancing the user experience and making it easier for individuals to comprehend the translated speech. The quality of TTS has a direct impact on the overall user experience of real-time language translation services.
For our real-time TTS needs, we'll employ the fantastic library called gTTS.
Streamlit
Streamlit is an open-source Python library designed to create interactive data applications, often referred to as dashboards. It empowers developers to build and share data apps simply and intuitively, eliminating the need for extensive web development expertise.
Streamlit apps are created as Python scripts, which are then executed within the Streamlit environment. The library offers a set of functions that can be utilized to add interactive elements to the app such as sliders, buttons, and drop-down menus. It also supports data visualization libraries like Matplotlib and Plotly, making it a breeze to incorporate charts and graphs into the app.
A standout feature of Streamlit is its real-time interactivity. As users engage with the app, the Python script runs in response, updating the app's output instantly. This characteristic makes Streamlit particularly well-suited for applications involving real-time data or requiring immediate feedback, such as machine learning models or data exploration tools and real-time translation.
Steps
To build this chat interface you will follow these few steps:
- Set up the environment: Start by setting up your project folder, installing necessary dependencies, and configuring environment variables.
- Set up Streamlit: Next, install Streamlit and create the initial user interface for your application.
- Integrate the speech-to-text functionality: In this step, you'll integrate speech-to-text (STT) capabilities using an external library.
- Integrate with the Groq API: Here, you'll integrate the Groq API to enable real-time translations in your application.
- Integrate the text-to-speech functionality: In this step, you'll integrate text-to-speech (TTS) capabilities using an external library.
- Testing the application: Try out your newly created application with a set of examples and perform the necessary tests.
- Deployment on Koyeb: Finally, deploy your application on the Koyeb platform.
Set up the environment
Let's start by creating a new project. To keep your Python dependencies organized you should create a virtual environment.
You can create and navigate into a local folder on your computer by typing:
# Create and move to the new folder
mkdir example-groq-translation
cd example-groq-translation
Afterwards, create and activate a new virtual environment by typing:
# Create a virtual environment
python -m venv venv
# Active the virtual environment (Windows)
.\venv\Scripts\activate.bat
# Active the virtual environment (Linux)
source ./venv/bin/activate
Now, you can install the required dependencies:
pip install python-decouple groq streamlit audio-recorder-streamlit faster-whisper gTTS
In terms of dependencies, we have included python-decouple for loading environment variables, streamlit and audio-recorder-streamlit for recording voice, faster-whisper for STT, gTTS for TTS, and groq for the real-time translation.
Don't forget to save your dependencies to the requirements.txt file:
pip freeze > requirements.txt
As mentioned before, you will need a Groq account and access to an API Key, if you don't have an account, you can create one here. After that, you can create a new API key.
With the API Key, you can now create a .env file to store it:
echo 'GROQ_API_KEY="<YOUR_GROQ_API_KEY>"' > .env
Set up Streamlit
In this step, you will set up the Streamlit UI that will allow users to speak, select a language, and see the translated text. Most of the code and logic for the project will reside in this file, so you can start by creating a main.py file:
# main.py
import streamlit as st
from audio_recorder_streamlit import audio_recorder
# Set page config
st.set_page_config(page_title='Groq Translator', page_icon='🎤')
# Set page title
st.title('Groq Translator')
languages = {
"Portuguese": "pt",
"Spanish": "es",
"German": "de",
"French": "fr",
"Italian": "it",
"Dutch": "nl",
"Russian": "ru",
"Japanese": "ja",
"Chinese": "zh",
"Korean": "ko"
}
# Language selection
option = st.selectbox(
"Language to translate to:",
languages,
index=None,
placeholder="Select language...",
)
# Record audio
audio_bytes = audio_recorder()
if audio_bytes and option:
# Display audio player
st.audio(audio_bytes, format="audio/wav")
# Save audio to file
with open('audio.wav', mode='wb') as f:
f.write(audio_bytes)
Here's a breakdown of the main code components:
- We define the page configuration with
st.set_page_config(), setting the page title to 'Groq Translator' and the page icon to a microphone emoji. - Next, we the page title to 'Groq Translator' using
st.title(). - We create a dictionary with languages our application will support (Portuguese, Spanish, German, French, Italian, Dutch, Russian, Japanese, Chinese, and Korean) as the keys. These are mapped to their two letter abbreviations that we will use later with
gTTS. - We create a select box using
st.selectbox()so the user can choose the language to translate to. - The
audio_recorder()function from theaudio_recorder_streamlitlibrary lets us record audio. If audio is recorded (i.e.,audio_bytesis not empty) and a language is selected (optionis notNone), it does the following:- It displays an audio player using
st.audio()to play back the recorded audio. - It saves the recorded audio to a file named 'audio.wav' in the current directory. The audio is saved in binary format, as indicated by the 'wb' mode in
open().
- It displays an audio player using
You can run the Streamlit application with:
streamlit run main.py
Click on the "Click to record" button and record a message. The recording will automatically stop once you finish your sentence.
You can then play back your recorded voice (make sure you have a language selected, even though we are not translating yet):
Integrate the speech-to-text functionality
The first step in translating from the voice recording is to transcribe it, meaning transforming the sound recording into written text.
For that, you will use the faster-whisper library, which is capable of transcribing English (and other languages) at a very fast speed even on a "normal" CPU.
Let's implement that functionality now by modifying the main.py file:
# main.py
import streamlit as st
from audio_recorder_streamlit import audio_recorder
from faster_whisper import WhisperModel # [!code ++]
import os # [!code ++]
# Set page title
...
# Load whisper model
model = WhisperModel("base", device="cpu", compute_type="int8", cpu_threads=int(os.cpu_count() / 2)) # [!code ++]
# Speech to text
def speech_to_text(audio_chunk): # [!code ++]
segments, info = model.transcribe(audio_chunk, beam_size=5) # [!code ++]
speech_text = " ".join([segment.text for segment in segments]) # [!code ++]
return speech_text # [!code ++]
# Record audio
...
# Save audio to file
...
# Speech to text
st.divider() # [!code ++]
with st.spinner('Transcribing...'): # [!code ++]
text = speech_to_text('audio.wav') # [!code ++]
st.subheader('Transcribed Text') # [!code ++]
st.write(text) # [!code ++]
Here's a breakdown of what the new code does:
- It imports the
WhisperModelclass from thefaster_whisperlibrary, which is used for speech-to-text transcription. It also imports theoslibrary to access system information. - It initializes a
WhisperModelinstance using the "base" model, with the device set to "cpu" and compute type set to "int8". The number of CPU threads to use is set to half of the available CPU cores on the system. - It defines a new function called
speech_to_text()that takes an audio chunk as input, transcribes it using theWhisperModelinstance, and returns the transcribed text. Thetranscribe()method returns a list of segments, each containing a transcribed text string. The function concatenates these strings into a single string using thejoin()method. - The
speech_to_text()function is called on the recorded audio (stored in theaudio.wavfile) to transcribe the speech. A divider is displayed usingst.divider(), and a spinner is shown usingst.spinner()while the transcription is being performed. The transcribed text is then displayed usingst.subheader()andst.write().
When you run the Streamlit application again, you should now see the transcribed text after you speak (make sure you have a language selected, even though we are not translating yet):
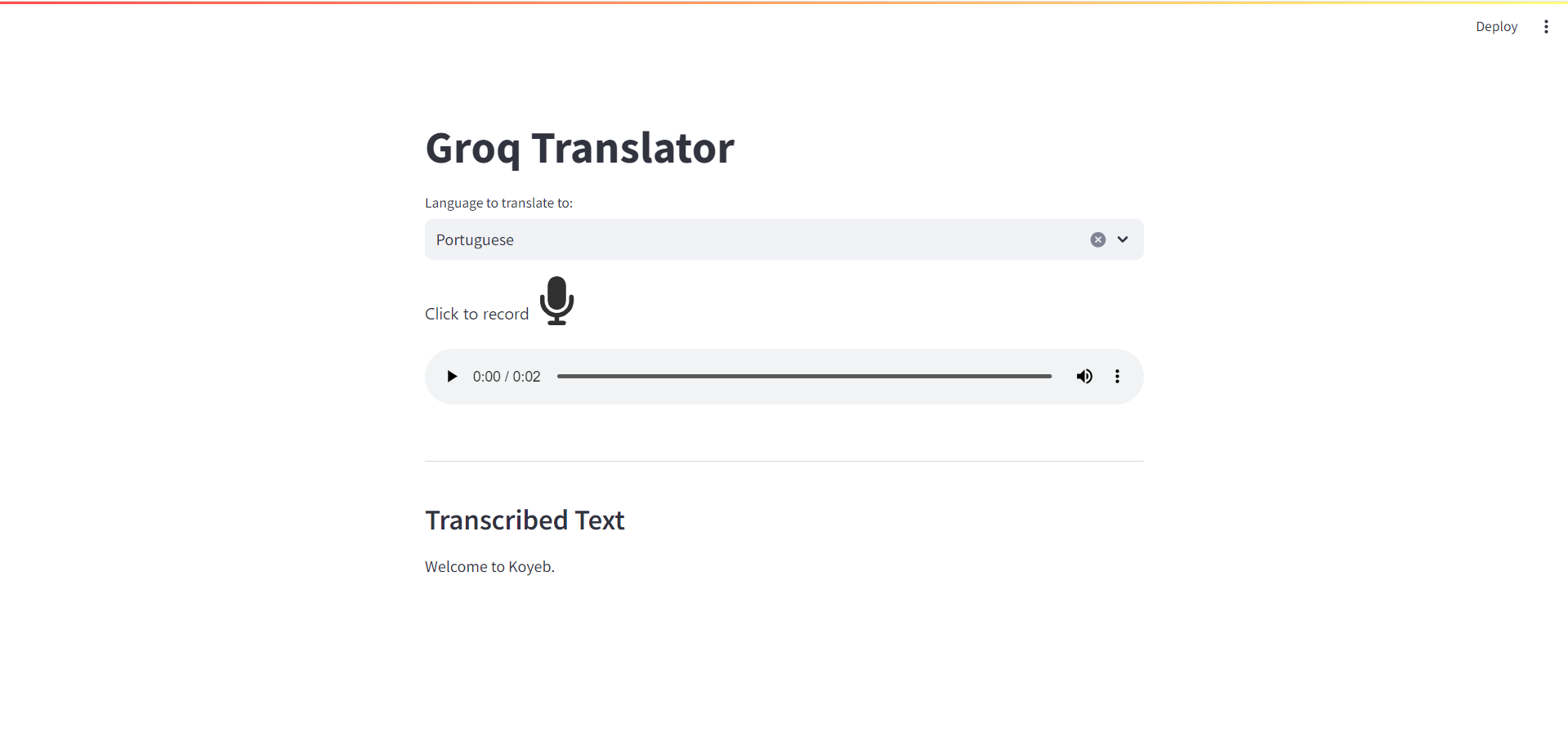
Note: It might take a few seconds to download the Whisper model the first time you run the application. Afterwards, the model will be in the cache and load times will be faster.
Integrate with the Groq API
With the transcribed text you can now integrate with the Groq API for ultra-fast translation. To keep this code organized and for easier understanding, you will place this functionality in a separate file.
Create a file called groq_translation.py and place this code inside:
# groq_translation.py
import json
from typing import Optional
from decouple import config
from groq import Groq
from pydantic import BaseModel
# Set up the Groq client
client = Groq(api_key=config("GROQ_API_KEY"))
# Model for the translation
class Translation(BaseModel):
text: str
comments: Optional[str] = None
# Translate text using the Groq API
def groq_translate(query, from_language, to_language):
# Create a chat completion
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": f"You are a helpful assistant that translates text from {from_language} to {to_language}."
f"You will only reply with the translation text and nothing else in JSON."
f" The JSON object must use the schema: {json.dumps(Translation.model_json_schema(), indent=2)}",
},
{
"role": "user",
"content": f"Translate '{query}' from {from_language} to {to_language}."
}
],
model="mixtral-8x7b-32768",
temperature=0.2,
max_tokens=1024,
stream=False,
response_format={"type": "json_object"},
)
# Return the translated text
return Translation.model_validate_json(chat_completion.choices[0].message.content)
This Python script defines a translation function using the Groq API. Here's a breakdown of what the code does:
- It imports the necessary libraries:
jsonfor working with JSON data,typingfor type hints,decouplefor loading environment variables,groqfor interacting with the Groq API, andpydanticfor data validation. - It sets up a Groq client instance using an API key loaded from an environment variable named
GROQ_API_KEY. - It defines a
Translationmodel usingpydanticto represent a translated text. The model has two attributes:text(a required string attribute) andcomments(an optional string attribute). - It defines a
groq_translate()function that takes three arguments:query(the text to translate),from_language(the source language), andto_language(the target language). The function uses the Groq client to create a chat completion, which sends a translation request to the Groq API. - The chat completion is created with a system message that sets the role of the assistant to translate text from the source language to the target language. The message also specifies the expected JSON schema for the response. The user message contains the translation request.
- The function sets "mixtral-8x7b-32768" (from Mistral AI) as the Groq model to use, the temperature to 0.2, the maximum number of tokens to 1024, and the stream option to False. It also sets the response format to a JSON object.
- The function uses
Translation.model_validate_json()to validate the content against theTranslationmodel schema. It returns the validated JSON object.
Now you can use this function in the main application file, main.py. Open the file and make the following modifications::
# main.py
. . .
from groq_translation import groq_translate # [!code ++]
# Record audio
...
# Speech to text
...
# Groq translation
st.divider() # [!code ++]
with st.spinner('Translating...'): # [!code ++]
translation = groq_translate(text, 'en', option) # [!code ++]
st.subheader('Translated Text to ' + option) # [!code ++]
st.write(translation.text) # [!code ++]
Here's a breakdown of what the new code does:
- It imports the
groq_translate()function from thegroq_translationmodule. - After transcribing the recorded audio to text, it calls the
groq_translate()function to translate the transcribed text from English to the selected target language (stored in theoptionvariable). - A divider is displayed using
st.divider(), and a spinner is shown usingst.spinner()while the translation is being performed. - The translated text is displayed using
st.subheader()andst.write(). The subheader includes the name of the target language.
If you run the application, you should now see the translation text:
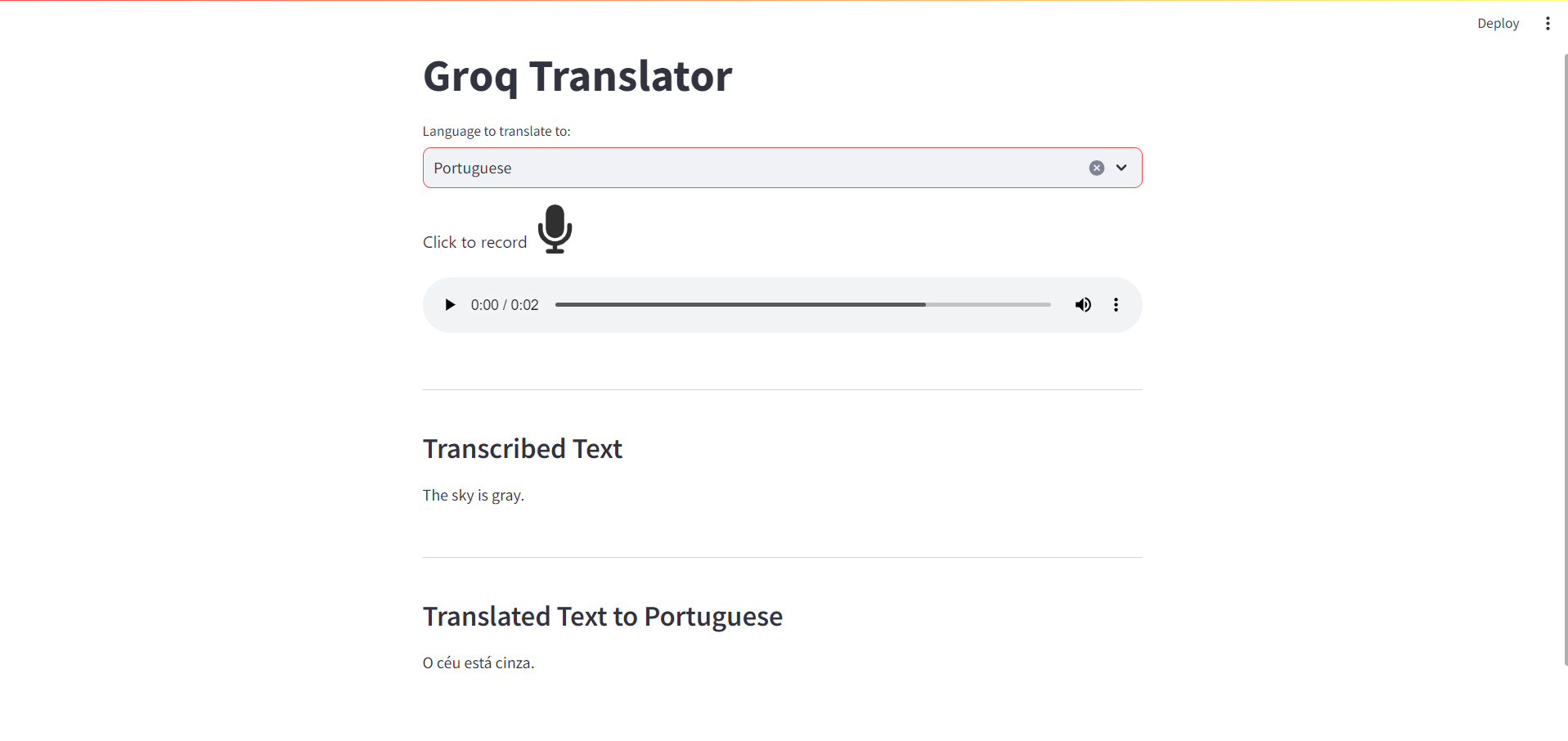
Integrate the text-to-speech functionality
The last remaining step is to speak the translated text and for that, you will use the gTTS library. In the main.py file, add the final piece of code:
# main.py
. . .
from gtts import gTTS # [!code ++]
# Speech to text
...
# Text to speech
def text_to_speech(translated_text, language): # [!code ++]
file_name = "speech.mp3" # [!code ++]
my_obj = gTTS(text=translated_text, lang=language) # [!code ++]
my_obj.save(file_name) # [!code ++]
return file_name # [!code ++]
# Record audio
...
# Speech to text
...
# Groq translation
...
# Text to speech
audio_file = text_to_speech(translation.text, languages[option]) # [!code ++]
st.audio(audio_file, format="audio/mp3") # [!code ++]
Here's a breakdown of what the new code does:
- It imports the
gTTSlibrary, which is used to convert text to speech. - It defines a new function
text_to_speech()that takes the stringstranslated_textandlanguageas input, converts thetranslated_textto speech in the providedlanguageusinggTTS, saves the speech as an MP3 file, and returns the file name. - After translating the transcribed text using
groq_translate(), it calls thetext_to_speech()function with the translation text and the two letter language abbreviation from thelanguagesdictionary thatgTTSrequires in order to convert the translated text to speech. - It displays an audio player using
st.audio()to play back the generated speech.
When you run the application, you should now have an audio player with the translated audio:
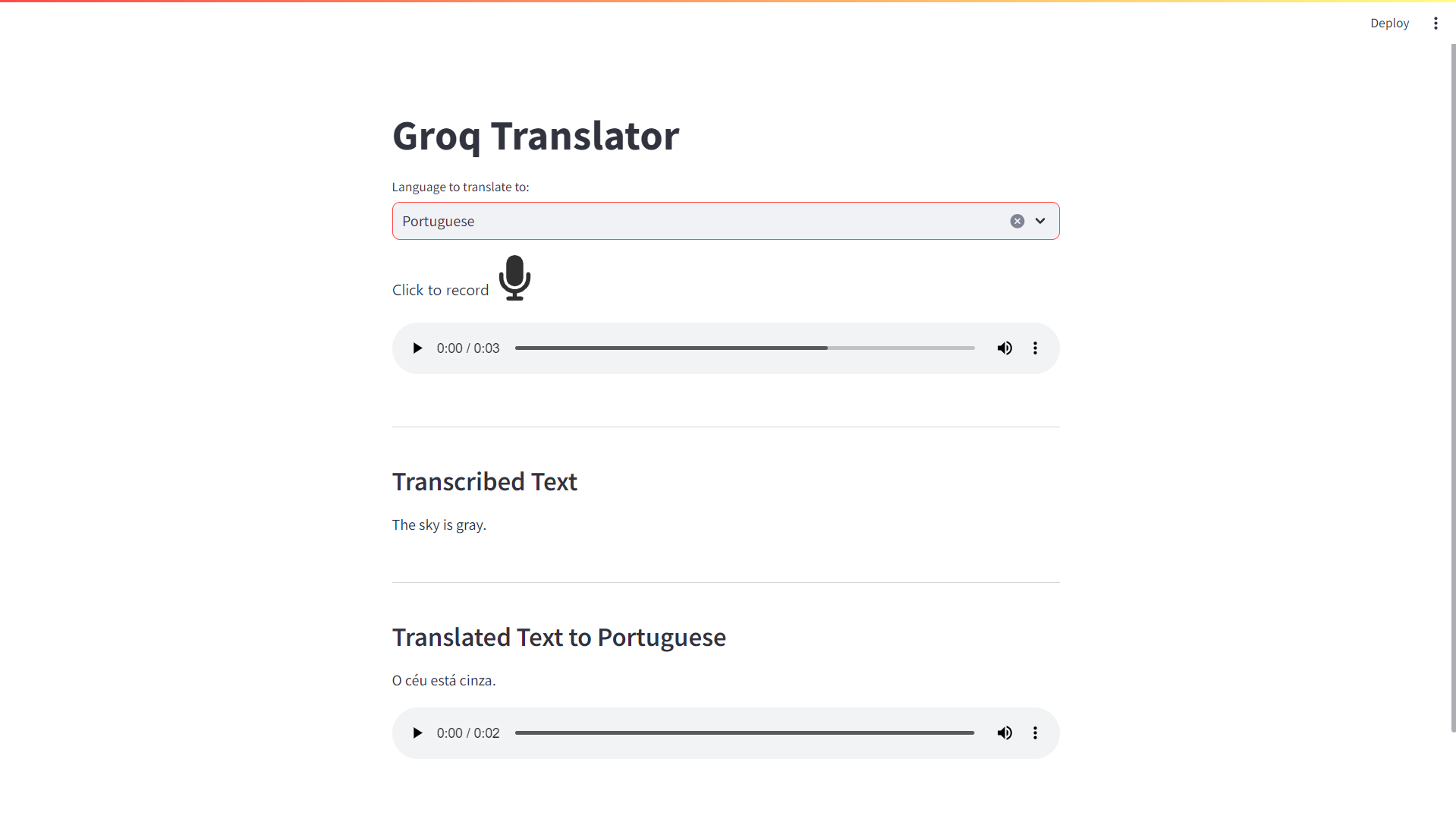
Testing the application
Let's see a couple of examples of the application and its translation capabilities:
Translating to German:
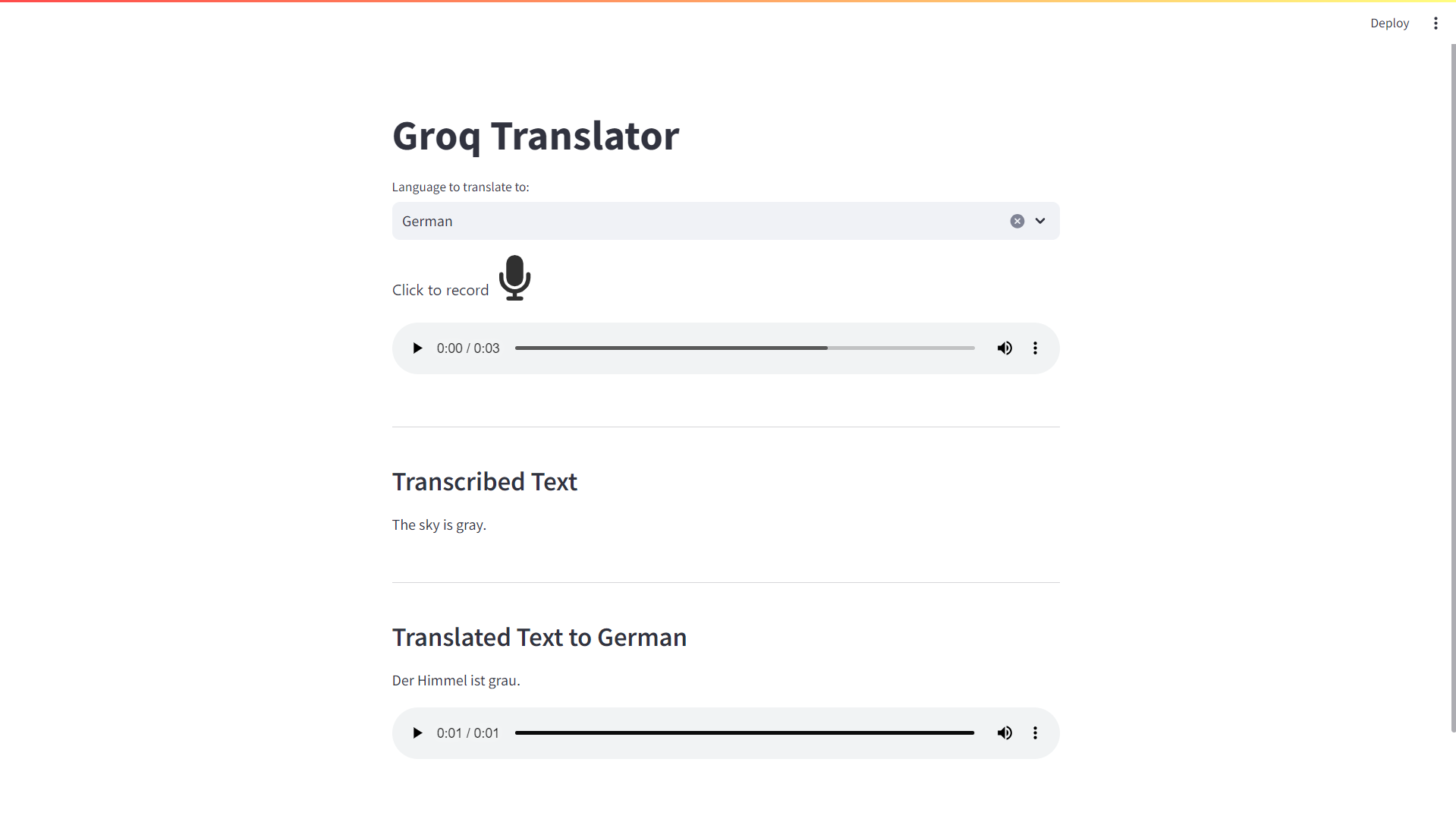
Translating to French:
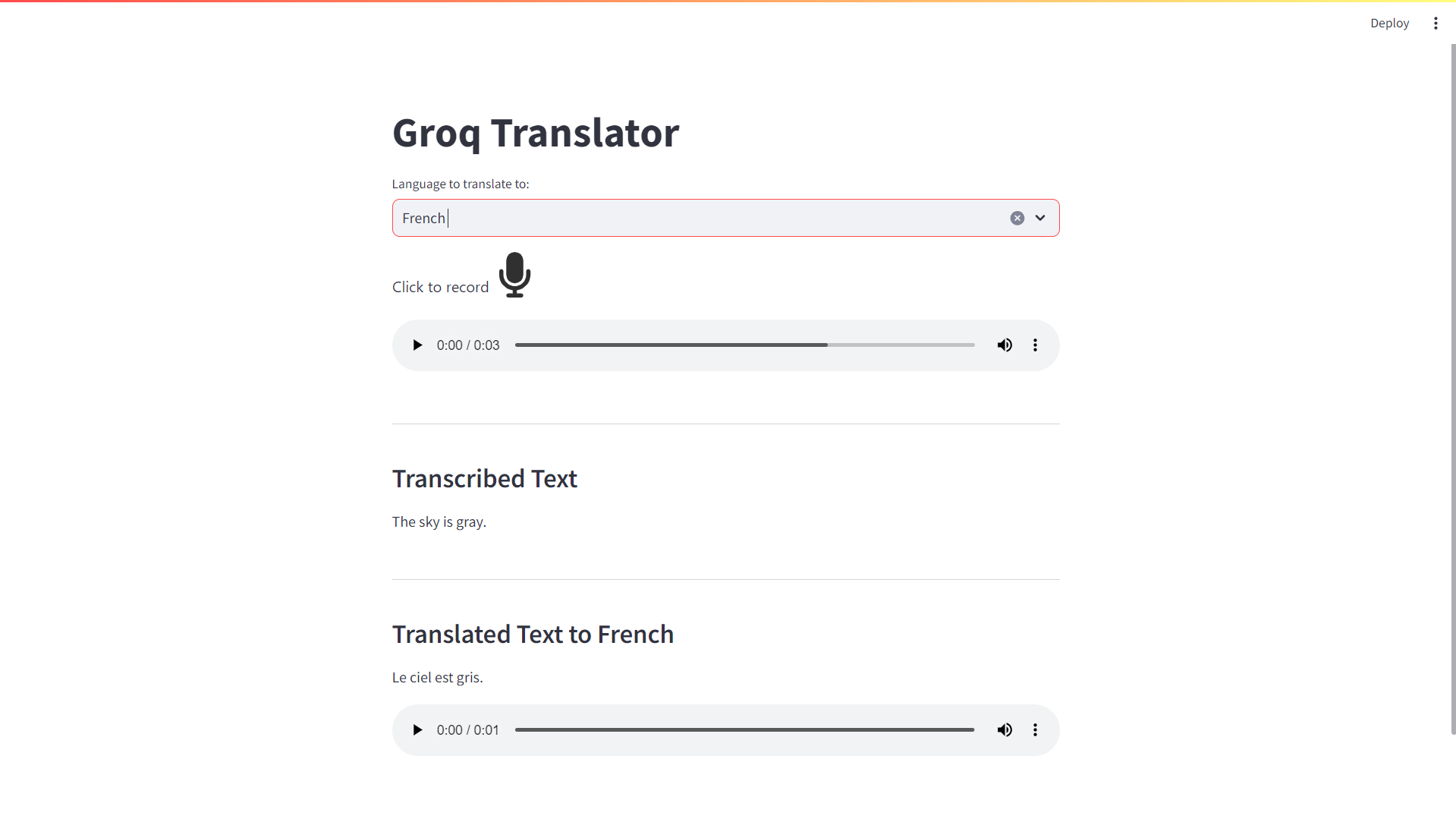
And even translating to Chinese:
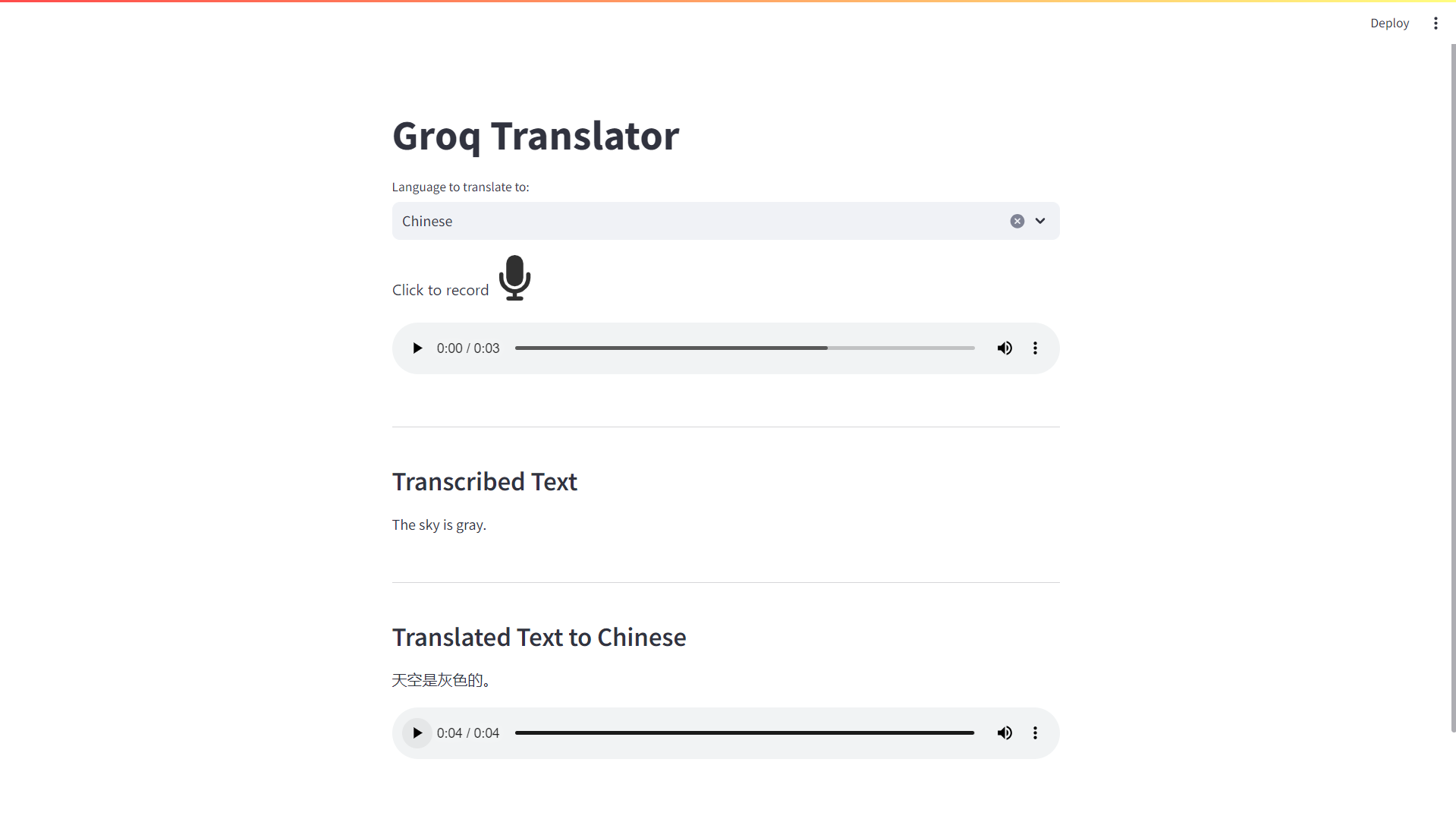
Deploy to Koyeb
Now that you have the application running locally you can also deploy it on Koyeb and make it available on the internet.
Create a new repository on your GitHub account so that you can push your code.
You can download a standard .gitignore file for Python from GitHub to exclude certain folders and files from being pushed to the repository:
curl -L https://raw.githubusercontent.com/github/gitignore/main/Python.gitignore -o .gitignore
Add the two audio files that our application produces during runtime so that we don't store those in the repository:
printf "%s\n" "audio.wav" "speech.mp3" >> .gitignore
Run the following commands in your terminal to commit and push your code to the repository:
git init
git add .
git commit -m "first commit"
git branch -M main
git remote add origin [Your GitHub repository URL]
git push -u origin main
You should now have all your local code in your remote repository. Now it is time to deploy the application.
Within the Koyeb control panel, while on the Overview tab, initiate the app creation and deployment process by clicking Create Web Service.
On the application deployment page:
- Select GitHub as your deployment method.
- Select your repository from the menu. Alternatively, deploy from the example repository associated with this tutorial by entering
https://github.com/koyeb/example-groq-translationin the public repository field. - Under Builder configure your run command by enabling the override toggle associated with the Run command field and entering
streamlit run main.py. - Under Environment variables and files, click Add variable to add your Groq API key as
GROQ_API_KEY. - Under Exposed ports, change the port selection to 8501, as used by Streamlit.
- In the Instance selection, select an Instance of type Small or larger.
- Under App and Service names, rename your App to whatever you'd like. For example,
groq-translation. Note the name will be used to create the public URL for this app. You can add a custom domain later if you'd like. - Finally, click the Deploy button.
Once the application is deployed, you can visit the Koyeb service URL (ending in .koyeb.app) to access the Streamlit application.
Conclusion
In conclusion, the combination of speech-to-text, the Groq API, and text-to-speech technologies can perform real-time multi-language translation, breaking down language barriers and enabling global communication.
This integration can have a significant impact across various sectors, making seamless communication possible between people speaking different languages. Despite challenges like accuracy and speed, advancements in AI and machine learning offer exciting future possibilities.
The new, fast LLM inference by Groq allows the use of its API in real-time applications when before it was not possible to use LLMs (Large Language Models) in this setting. In this new era of communication, language is a bridge, not a barrier.

