Using YOLO for Real-Time Object Detection with Koyeb GPUs
Introduction
Welcome to this comprehensive guide on implementing real-time object detection using the YOLO (You Only Look Once) algorithm. This technology represents a leap forward in how we detect objects in real time, making it an invaluable tool in surveillance, robotics, and autonomous driving fields.
In this guide, we will walk through the theory behind YOLO, how it works, and how to implement it in your projects for your real-time object detection. We'll also see real-world applications of YOLO in action, showcasing its power and versatility.
You can consult the project repository as work through this guide. You can deploy the YOLO object detection application as built in this tutorial using the Deploy to Koyeb button below:

Understanding YOLO (You Only Look Once)
YOLO, an acronym for "You Only Look Once", is an innovative approach to object detection. The primary difference between YOLO and other object detection algorithms is in the way it handles object detection.
While most algorithms process an image multiple times to detect objects, YOLO uses a single pass, prompting the name "You Only Look Once".
This is a simplified breakdown of how it works:
- First, the entire image is divided into a grid. Each cell in the grid evaluated individually for predicting objects within its boundaries.
- For each grid cell, YOLO generates a number of bounding boxes. A bounding box is a rectangular box that can be computed to contain an object. Each bounding box comes with a confidence score, representing how certain YOLO is that the predicted box encloses some object.
- Along with the bounding box, YOLO also provides the class of the object that it believes exists within the box. For example, it might claim that the object is a cat, dog, car, or any other type of object it has been trained to recognize.
- After making all of the predictions, YOLO selects the bounding box with the highest confidence level and the associated object class as its final prediction.
YOLO's unique approach allows it to detect objects in real-time, making it a great choice for many computer vision tasks.
Requirements
Before diving into building the object detection application with YOLO, it's important to ensure that you have the necessary tools and knowledge. This section outlines the prerequisites you'll need to follow the guide successfully:
- A Koyeb account is required to deploy.
- Knowledge of Python programming to understand the scripts we will create.
- A GitHub account: to store the code and trigger deployments to Koyeb GPUs.
Steps
There are several implementations of the YOLO algorithm available, but for ease-of-use, we will use the Ultralytics implementation in this guide. We will implement and test the code locally and then deploy to Koyeb's GPUs for higher inference speed.
To get started, create a project directory and then create and activate a new virtual environment within:
mkdir example-yolo
cd example-yolo
python -m venv venv
source venv/bin/activate
Now that the virtual environment and project directory are set up, make sure you have the necessary libraries and a version of YOLO installed. Visit PyTorch's getting started page to find the appropriate commands for your operating system. For this guide, we will use the Stable build, the Pip package manager, the Python language, and CUDA 12.1 as the compute platform. The commands to run will depend on your local operating system:
# Linux
pip install torch torchvision torchaudio
# Windows
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
Next, install the Ultralytics YOLO library:
pip install ultralytics opencv-python
In addition to installing the YOLO implementation from Ultralytics, this also installs OpenCV for image processing.
We will be using Streamlit to build the application UI. In order to support non-local access to the webcam (when deployed to the Koyeb cloud, for instance), you will also need to install a few additional libraries:
pip install streamlit streamlit-webrtc pyarrow
You now have all the necessary dependencies installed.
Implementing YOLO for Real-Time Object Detection
Let's now create a simple Streamlit application that shows the YOLO ease of use for object detection, you can create a file called web.py:
from streamlit_webrtc import webrtc_streamer, WebRtcMode
from ultralytics import YOLO
import av
# Load the YOLOv8 model for Object Detection
model = YOLO("yolov8n.pt")
# Function to process each frame of the video stream
def process_frame(frame):
# Read image from the frame with PyAV
img = frame.to_ndarray(format="bgr24")
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(img, tracker="bytetrack.yaml")
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Return the annotated frame
return av.VideoFrame.from_ndarray(annotated_frame, format="bgr24")
# Create a WebRTC video streamer with the process_frame callback
webrtc_streamer(key="streamer", video_frame_callback=process_frame, sendback_audio=False,
media_stream_constraints={"video": True, "audio": False},
async_processing=True,
mode=WebRtcMode.SENDRECV,
rtc_configuration={
"iceServers": [{"urls": ["stun:stun.l.google.com:19302"]}]
}
)
Here's a breakdown of the code:
- Import the necessary libraries:
streamlit_webrtcis used for real-time video streamingultralyticsis used for loading the YOLOv8 modelavis used for handling video frames
- Load the YOLOv8 model with the
yolov8n.ptweights. We will use this model to detect objects in the video frames. - Define the
process_framefunction. This function takes a video frame as input. It converts the frame to an image using PyAV, and then applies the YOLOv8 model to detect objects in the image. The model uses the ByteTrack tracker to keep track of objects between frames. The detection results are then visualized on the frame, and the annotated frame is returned. - Call the
webrtc_streamerfunction to create a WebRTC video streamer. We pass theprocess_framefunction as thevideo_frame_callbackargument so that it will be called for each frame of the video stream. Themedia_stream_constraintsargument is used to specify that only the video should be streamed, not audio. Theasync_processingargument is set toTrueto enable processing frames in parallel with the streaming. Themodeargument is set toWebRtcMode.SENDRECV, which sets the streamer to both send and receive video. We also define also anrtc_configurationso that it can use Google's free STUN servers so that it works when running in the cloud.
You can run the application locally with:
streamlit run web.py
Once the application launches, access it by navigating to http://localhost:8501/ in your browser.
The YOLOv8 model has the capability to not only detect objects in a frame but also track them across frames. This is particularly useful in applications like video surveillance, autonomous vehicles, and human-computer interaction.
For tracking objects, YOLOv8 provides two options: BoT-SORT and ByteTrack.
- BoT-SORT is an extension of the original SORT (Simple Online Realtime Tracker) algorithm that also considers the motion history of objects for tracking. It uses the Kalman filter to predict the future position of objects and the Hungarian algorithm for data association. To enable BoT-SORT in YOLOv8, you need to use the
botsort.yamlconfiguration file. - ByteTrack is a more recent tracking algorithm that is designed to handle occlusions and overlapping objects better. It uses a byte-level representation of objects and a motion model to predict the future position of objects. To enable ByteTrack in YOLOv8, use the
bytetrack.yamlconfiguration file.
Let's expand the initial application and allow users to upload videos for processing in addition to real-time processing:
import os # [!code ++]
import tempfile # [!code ++]
import cv2 # [!code ++]
from streamlit_webrtc import webrtc_streamer, WebRtcMode
import streamlit as st # [!code ++]
from ultralytics import YOLO
import av
# Load the YOLOv8 model for Object Detection
model = YOLO("yolov8n.pt")
# Function to process each frame of the video stream
def process_frame(frame):
# Read image from the frame with PyAV
img = frame.to_ndarray(format="bgr24")
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(img, tracker="bytetrack.yaml")
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Return the annotated frame
return av.VideoFrame.from_ndarray(annotated_frame, format="bgr24")
# Function to process the video with OpenCV
def process_video(video_file): # [!code ++]
# Open the video file
cap = cv2.VideoCapture(video_file) # [!code ++]
# Set the frame width and height
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280) # [!code ++]
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720) # [!code ++]
# Loop through the video frames
while cap.isOpened(): # [!code ++]
# Read a frame from the video
success, frame = cap.read() # [!code ++]
if success: # [!code ++]
# Run YOLOv8 tracking on the frame, persisting tracks between frames
results = model.track(frame, tracker="bytetrack.yaml") # [!code ++]
# Visualize the results on the frame
annotated_frame = results[0].plot() # [!code ++]
# Display the annotated frame
frame = cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB) # [!code ++]
frame_placeholder.image(frame, channels="RGB") # [!code ++]
else: # [!code ++]
# Break the loop if the end of the video is reached
break # [!code ++]
# Release the video capture object and close the display window
cap.release() # [!code ++]
# Create a WebRTC video streamer with the process_frame callback
webrtc_streamer(key="streamer", video_frame_callback=process_frame, sendback_audio=False,
media_stream_constraints={"video": True, "audio": False},
async_processing=True,
mode=WebRtcMode.SENDRECV,
rtc_configuration={
"iceServers": [{"urls": ["stun:stun.l.google.com:19302"]}]
}
)
# File upload for uploading the video file, placeholder for displaying the frames and button to start processing
file = st.file_uploader("Upload a video file", type=["mp4", "mov", "avi", "mkv"]) # [!code ++]
button = st.button("Process Video") # [!code ++]
frame_placeholder = st.empty() # [!code ++]
# If the button is clicked and a file is uploaded, save the file to a temporary directory and process the video
if button: # [!code ++]
# Save the file to a temporary directory
temp_dir = tempfile.mkdtemp() # [!code ++]
path = os.path.join(temp_dir, file.name) # [!code ++]
with open(path, "wb") as f: # [!code ++]
f.write(file.getvalue()) # [!code ++]
# Process the video
process_video(path) # [!code ++]
Here's a breakdown of the new code:
- Import the new libraries:
cv2is for handling video files with OpenCVstreamlitis to create the web application
- Load the YOLOv8 model with the
yolov8n.ptweights. We will use this model to detect objects in the video frames. - Define the
process_videofunction. This function takes a video file path as input and opens the video file using OpenCV. It then loops through the video frames and applies the YOLOv8 model to detect objects in each frame. It returns the frame with the detection results displayed on it. - Create a Streamlit file uploader to allow the user to upload a video file. We create a Streamlit button to start the video processing. When the button is clicked and a file is uploaded, the file is saved to a temporary directory and then processed using the
process_videofunction.
Real-World applications of YOLO object detection
The Ultralytics YOLO documentation outlines several specific tasks that can be performed using the YOLO algorithm. Let's explore some of these tasks and their applications in real-world scenarios.
Object Counting
Object counting is the process of simply counting the number of instances of a specific object within an image or video. This task is particularly useful in scenarios like:
- crowd management: Estimating the number of people in a crowded area.
- inventory management: Counting products on shelves in a retail environment.
- wildlife monitoring: Tracking the number of animals in a specific area for ecological studies.
Code Example
Let's see the code changes we could make to our web.py file in order to support object counting:
... updated imports ...
from ultralytics import YOLO # [!code --]
from ultralytics import YOLO, solutions # [!code ++]
... previous code ...
# Function to count objects in the video
def count_objects(video_file): # [!code ++]
# Define region points
region_points = [(20, 150), (400, 150), (400, 350), (20, 350)] # [!code ++]
# Init Object Counter
counter = solutions.ObjectCounter( # [!code ++]
view_img=False, # [!code ++]
reg_pts=region_points, # [!code ++]
names=model.names, # [!code ++]
draw_tracks=True, # [!code ++]
line_thickness=2, # [!code ++]
) # [!code ++]
# Open the video file
cap = cv2.VideoCapture(video_file) # [!code ++]
# Loop through the video frames
while cap.isOpened(): # [!code ++]
# Read a frame from the video
success, frame = cap.read() # [!code ++]
if success: # [!code ++]
# Run YOLOv8 tracking on the frame, persisting tracks between frames
tracks = model.track(frame, persist=True, show=False) # [!code ++]
# Count objects in the frame
annotated_frame = counter.start_counting(frame, tracks) # [!code ++]
# Display the annotated frame
frame = cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB) # [!code ++]
frame_placeholder.image(frame, channels="RGB") # [!code ++]
else: # [!code ++]
# Break the loop if the end of the video is reached
break # [!code ++]
# Release the video capture object
cap.release() # [!code ++]
# File upload for uploading the video file, placeholder for displaying the frames and button to start processing
... previous code ...
button_count = st.button("Count Objects") # [!code ++]
frame_placeholder = st.empty()
# If the button is clicked and a file is uploaded, save the file to a temporary directory and process the video
if button:
... previous code ...
if button_count: # [!code ++]
# Save the file to a temporary directory
temp_dir = tempfile.mkdtemp() # [!code ++]
path = os.path.join(temp_dir, file.name) # [!code ++]
with open(path, "wb") as f: # [!code ++]
f.write(file.getvalue()) # [!code ++]
# Count objects in the video
count_objects(path) # [!code ++]
Here's a breakdown of the new code:
- Add the
solutionsclass to the imports fromultralytics. This class contains pre-made solutions from Ultralytics likeObjectCounter. - Define the
count_objects(video_file)function. This function takes a video file as input and processes it to count objects. Inside the function, we do the following:- Define the
region_pointsvariable. This variable represents the region of interest (ROI): the coordinates of the region in the video frame where the objects are to be counted. - Initialize the object counter with
solutions.ObjectCounter. This class is responsible for counting objects that pass through the defined region. It takes parameters such asview_img,reg_pts,names,draw_tracks, andline_thickness. - Open the uploaded video using OpenCV's
cv2.VideoCapture(video_file)function. - Loop through the video frame-by-frame until the video is finished. In each iteration, a frame is read from the video. If the frame is successfully read, YOLOv8 tracking is applied to the frame with
model.track(frame, persist=True, show=False). Thecounter.start_counting(frame, tracks)method is called to count objects in the frame and the annotated frame is then displayed. - Release the video capture object with
cap.release()once the video is finished.
- Define the
- Add a "Count Objects" button and an empty placeholder for displaying the video frames to the user interface. When the button is clicked, the video file is saved to a temporary directory, and the
count_objects(path)function is called to process the video.
Let's see an example of object counting:
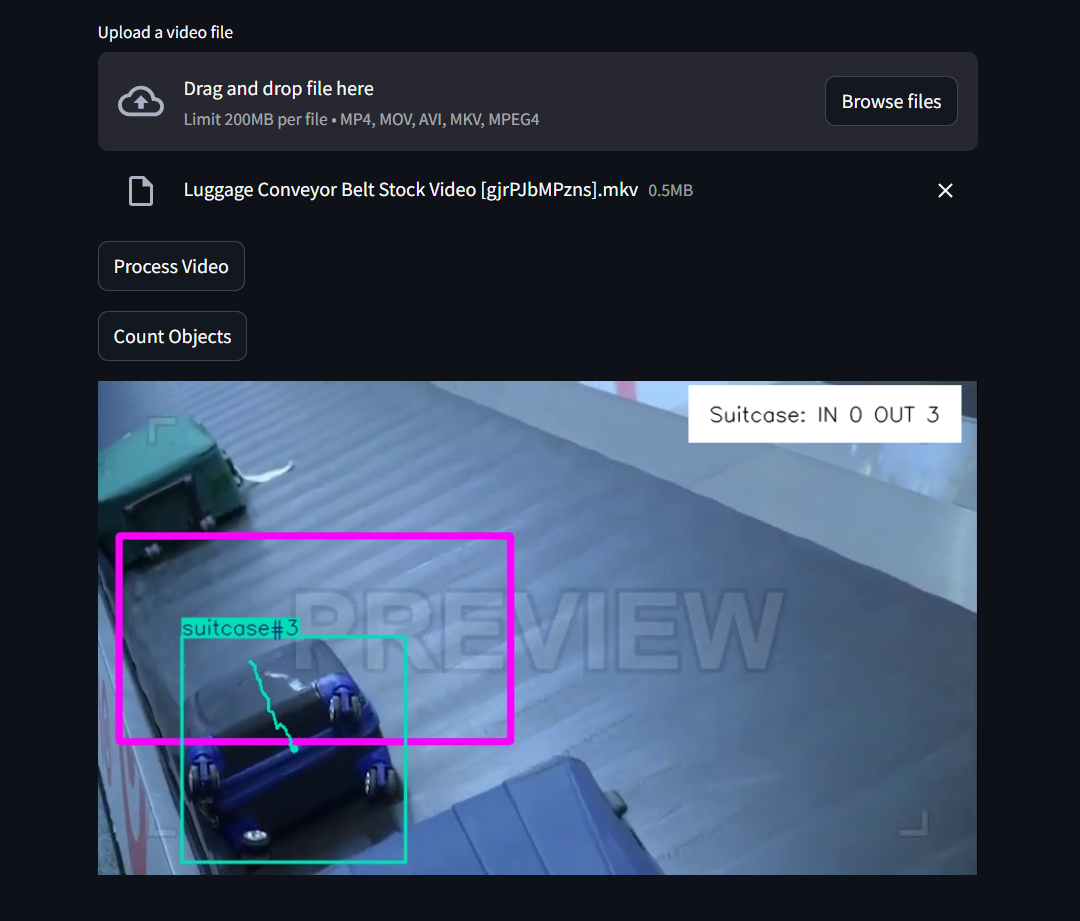
Object Cropping
Object cropping identifies and extracts specific objects from an image or video. This task allows you to create smaller images containing only the objects of interest, which can be useful for:
- image editing: Isolating objects for graphic design purposes.
- data augmentation: Creating additional training data for machine learning models.
- focus enhancement: Highlighting objects in presentations or reports.
Code Example
Let's see the code changes we can make to to the web.py file in order to support object cropping:
... added imports ...
from ultralytics.utils.plotting import Annotator, colors # [!code ++]
... previous code ...
# Function to crop objects in the video
def crop_objects(video_file): # [!code ++]
# Open the video file
cap = cv2.VideoCapture(video_file) # [!code ++]
with frame_placeholder.container(): # [!code ++]
# Loop through the video frames
while cap.isOpened(): # [!code ++]
# Read a frame from the video
success, frame = cap.read() # [!code ++]
if success: # [!code ++]
# Run YOLOv8 tracking on the frame
results = model.predict(frame, show=False) # [!code ++]
# Retrieve the bounding boxes and class labels
boxes = results[0].boxes.xyxy.cpu().tolist() # [!code ++]
clss = results[0].boxes.cls.cpu().tolist() # [!code ++]
# Create an Annotator object for drawing bounding boxes
annotator = Annotator(frame, line_width=2, example=model.names) # [!code ++]
# If boxes are detected, crop the objects and save them to a directory
if boxes is not None: # [!code ++]
# Iterate over the detected boxes and class labels
for box, cls in zip(boxes, clss): # [!code ++]
# Draw the bounding box on the frame
annotator.box_label(box, color=colors(int(cls), True), label=model.names[int(cls)]) # [!code ++]
# Crop the object from the frame
annotated_frame = frame[int(box[1]): int(box[3]), int(box[0]): int(box[2])] # [!code ++]
# Display the annotated frame
if annotated_frame.shape[0] > 0 and annotated_frame.shape[1] > 0: # [!code ++]
frame = cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB) # [!code ++]
st.image(frame, channels="RGB") # [!code ++]
else: # [!code ++]
# Break the loop if the end of the video is reached
break # [!code ++]
# Release the video capture object
cap.release() # [!code ++]
# File upload for uploading the video file, placeholder for displaying the frames and button to start processing
... previous code ...
button_crop = st.button("Crop Objects") # [!code ++]
frame_placeholder = st.empty()
# If the button is clicked and a file is uploaded, save the file to a temporary directory and process the video
if button:
... previous code ...
# If the button is clicked and a file is uploaded, save the file to a temporary directory and count the objects
if button_count:
... previous code ...
# If the button is clicked and a file is uploaded, save the file to a temporary directory and crop the objects
if button_crop: # [!code ++]
# Save the file to a temporary directory
temp_dir = tempfile.mkdtemp() # [!code ++]
path = os.path.join(temp_dir, file.name) # [!code ++]
with open(path, "wb") as f: # [!code ++]
f.write(file.getvalue()) # [!code ++]
# Count objects in the video
crop_objects(path) # [!code ++]
Here's a breakdown of the code:
- Import the new libraries. Import the
Annotatorandcolorsclasses fromultralytics.utils.plotting. These classes draw bounding boxes and retrieve colors for the bounding boxes, respectively. - Define the
crop_objects(video_file)function. This function takes a video file as input and processes it to crop objects. Inside the function, we do the following:- Open the uploaded video using OpenCV's
cv2.VideoCapture(video_file)function. - Loop through the video frame-by-frame until the video is finished. In each iteration, a frame is read from the video. If the frame is successfully read, YOLOv8 detection is applied to the frame with
model.predict(frame, show=False)and the bounding boxes and class labels are retrieved. - Crop the object. If bounding boxes are detected, an
Annotatorobject is created and, for each bounding box, the object is cropped from the frame and displayed. The original frame with the bounding boxes is not displayed. - Release the video capture object with
cap.release()once the video is finished.
- Open the uploaded video using OpenCV's
- Add a "Crop Objects" button and an empty placeholder for displaying the video frames to the user interface. When the button is clicked, the video file is saved to a temporary directory, and the
crop_objects(path)function is called to process the video.
Let's see an example of object cropping:

Object Blurring
Object blurring detects and blurs specific objects within an image or video. This task is essential for maintaining privacy and confidentiality in various applications, including:
- privacy protection: Blurring faces or license plates in surveillance footage.
- hiding sensitive information: Concealing confidential information in documents or presentations.
- anonymization: Ensuring individuals' identities are not revealed in public datasets.
Code Example
Let's see the code changes we need to make to our web.py file in order to support object blurring:
... previous code ...
# Function to blur objects in the video
def blur_objects(video_file): # [!code ++]
# Blur ratio
blur_ratio = 50 # [!code ++]
# Open the video file
cap = cv2.VideoCapture(video_file) # [!code ++]
# Loop through the video frames
while cap.isOpened(): # [!code ++]
# Read a frame from the video
success, frame = cap.read() # [!code ++]
if success: # [!code ++]
# Run YOLOv8 tracking on the frame
results = model.predict(frame, show=False) # [!code ++]
# Retrieve the bounding boxes and class labels
boxes = results[0].boxes.xyxy.cpu().tolist() # [!code ++]
clss = results[0].boxes.cls.cpu().tolist() # [!code ++]
# Create an Annotator object for drawing bounding boxes
annotator = Annotator(frame, line_width=2, example=model.names) # [!code ++]
if boxes is not None: # [!code ++]
for box, cls in zip(boxes, clss): # [!code ++]
annotator.box_label(box, color=colors(int(cls), True), label=model.names[int(cls)]) # [!code ++]
obj = frame[int(box[1]): int(box[3]), int(box[0]): int(box[2])] # [!code ++]
blur_obj = cv2.blur(obj, (blur_ratio, blur_ratio)) # [!code ++]
frame[int(box[1]): int(box[3]), int(box[0]): int(box[2])] = blur_obj # [!code ++]
# Display the annotated frame
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # [!code ++]
frame_placeholder.image(frame, channels="RGB") # [!code ++]
else: # [!code ++]
# Break the loop if the end of the video is reached
break # [!code ++]
# Release the video capture object
cap.release() # [!code ++]
# File upload for uploading the video file, placeholder for displaying the frames and button to start processing
... previous code ...
button_blur = st.button("Blur Objects") # [!code ++]
frame_placeholder = st.empty()
# If the button is clicked and a file is uploaded, save the file to a temporary directory and process the video
if button:
... previous code ...
# If the button is clicked and a file is uploaded, save the file to a temporary directory and count the objects
if button_count:
... previous code ...
# If the button is clicked and a file is uploaded, save the file to a temporary directory and crop the objects
if button_crop:
... previous code ..
# If the button is clicked and a file is uploaded, save the file to a temporary directory and blur the objects
if button_blur: # [!code ++]
# Save the file to a temporary directory
temp_dir = tempfile.mkdtemp() # [!code ++]
path = os.path.join(temp_dir, file.name) # [!code ++]
with open(path, "wb") as f: # [!code ++]
f.write(file.getvalue()) # [!code ++]
# Count objects in the video
blur_objects(path) # [!code ++]
Here's a breakdown of the code:
- Define the
blur_objects(video_file)function. This function takes a video file as input and processes it to blur objects. Inside the function, we do the following:- Define the
blur_ratiovariable. This variable represents the intensity of the blur effect. - Open the uploaded video using OpenCV's
cv2.VideoCapture(video_file)function. - Loop through the video frame-by-frame until the video is finished. In each iteration, a frame is read from the video. If the frame is successfully read, YOLOv8 detection is applied to the frame with
model.predict(frame, show=False)and the bounding boxes and class labels are retrieved. - Blur the object. If bounding boxes are detected, an
Annotatorobject is created and, for each bounding box, the object is cropped from the frame, blurred using OpenCV'scv2.blur()function, and then placed back in the original frame. The annotated frame with the blurred objects is then displayed. - Release the video capture object with
cap.release()once the video is finished.
- Define the
- Add a "Blur Objects" button and an empty placeholder for displaying the frames with blurred objects. When the button is clicked, the video file is saved to a temporary directory, and the
blur_objects(path)function is called to process the video.
Let's see an example of object blurring:
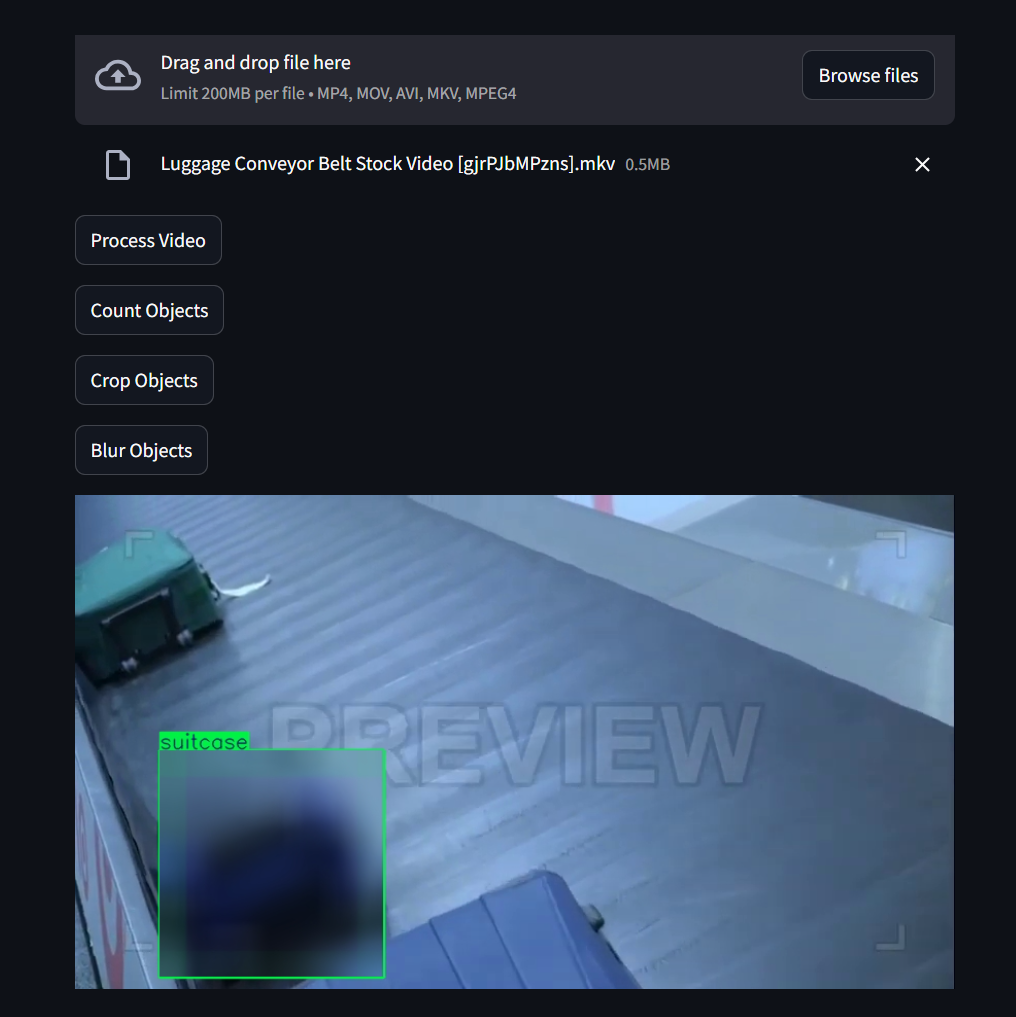
Deploy to Koyeb's GPUs
Now that we have the application running locally, it is time to make use of Koyeb's high-performance GPUs to increase the inference processing speed.
Before we do that, we need to create a Dockerfile to install and configure the necessary code and dependencies.
First, create a requirements.txt file with versions of the packages we installed earlier that will work in the cloud:
opencv-python-headless
streamlit
streamlit-webrtc
pyarrow
torch
torchvision
torchaudio
matplotlib
numpy<2.0.0
pyyaml
scipy
seaborn
tqdm
ultralytics-thop
psutil
py-cpuinfo
contourpy
cycler
fonttools
kiwisolver
pyparsing
This list includes all of the project's requirements, including the dependencies of the ultralytics package. However, you may notice that we do not list ultralytics itself. That's because the ultralytics package depends explicitly on opencv-python, which won't work in a headless environment like Koyeb.
Instead, we install opencv-python-headless as a workable substitute along with all of the package's other dependencies. Afterwards, in the Dockerfile, we will install ultralytics separately with the --no-deps flag. In this way we can install all of the package's dependencies ahead of time, substituting opencv-python-headless for opencv-python, to avoid conflicts with ultralytics stated dependencies.
Next, create a new Dockerfile in your project directory with the following content:
# Use the official Python base image
FROM python:3.12
# Copy the requirements file
COPY requirements.txt .
# Install the dependencies
RUN pip install --upgrade pip && pip install -r requirements.txt
RUN pip install --no-deps ultralytics
# Copy the rest of the application code
COPY web.py .
# Expose port 8501
EXPOSE 8501
# Set the entry point for the container
CMD ["streamlit", "run", "web.py"]
Let's examine the Dockerfile in detail:
FROM python:3.12: This line specifies the base image for the Docker image. In this case, it's the official Python 3.12 image.COPY requirements.txt .: This line copies therequirements.txtfile from the local machine to the current working directory of the Docker image.RUN pip install --upgrade pip && pip install -r requirements.txt: This line upgrades pip, the Python package installer, to the latest version and then uses it to install all of the Python dependencies listed in therequirements.txtfile.RUN pip install --no-deps ultralytics: This line installsultralyticswithout dependencies to avoid installingopencv-python. We can do this because therequirements.txtfile already manually installs all of the dependencies and provides a workable substitute foropencv-python.COPY web.py .: This line copies theweb.pyfile from the local machine to the Docker image in the current directory.EXPOSE 8501: This line specifies that the Docker container will listen on port 8501.CMD ["streamlit", "run", "web.py"]: This is the command that will be run when the Docker container starts. It starts the Streamlit app by running theweb.pyscript.
Now your project is ready to deploy on GPUs from Koyeb. The final step is to create a repository on your GitHub account.
Download the standard Python .gitignore file from GitHub to exclude certain folders and files from being pushed to the repository:
curl -L https://raw.githubusercontent.com/github/gitignore/main/Python.gitignore -o .gitignore
Add a line to avoid committing the yolov8n.pt file that the application creates:
echo "yolov8n.pt" >> .gitignore
Now, create a new repository on GitHub and run the following commands in your terminal to commit and push your code to the repository:
echo "# Yolo Real Time" >> README.md
git init
git add .
git commit -m "First Commit"
git branch -M main
git remote add origin [Your GitHub repository URL]
git push -u origin main
All of your local code should now be present in the remote repository. You can now deploy the application to Koyeb.
In the Koyeb control panel, on the Overview tab, initiate the app creation and deployment process by clicking Create Service and then Create web service:
- Select GitHub as the deployment source.
- Choose the repository where your code resides. For example,
YoloRealTime. - Select the GPU Instances and choose your Instance type, for example
RTX-4000-SFF-ADA. - In the Builder section, select Dockerfile.
- In the Exposed ports section, change the port to
8501. - Give the Service your preferred name.
- Click Deploy.
During the deployment process, it may take a few minutes to build the Docker image from the Dockerfile and upload it to Koyeb's container registry. After deployment, you can access the Streamlit application using your Koyeb application's public URL. Please note that when running in the cloud, the video image from a webcam might take several of seconds to start streaming since it needs to connect with the STUN servers.
Conclusion
In this guide, we learned about real-time object detection using the YOLO (You Only Look Once) algorithm. We started by discussing areas where real-time detection is important, such as in surveillance, robotics, and self-driving cars and why its ability to process images in a single pass makes it a good tool for real-time applications.
Afterwards, we took a look at how YOLO works by explaining its grid-based prediction system and how it manages to predict bounding boxes and class probabilities at the same time. Throughout the guide we explored advanced tasks YOLO excels at like object counting, cropping, blurring, segmentation, tracking, and action recognition. These tasks show how versatile and powerful YOLO is in handling complex real-world situations.
Finally, we gave practical advice on how to use Docker to deploy YOLO, making it easy to run YOLO applications in a consistent and reproducible environment. We used this to deploy and run the application on high-performance GPUS on Koyeb. As YOLO and real-time object detection continue to improve, they will become even more useful and have more applications. The ability to capitalize on these advancements with by executing on high-performance hardware may lead to exciting breakthroughs in many industries.

