Deploy AI Infrastructure in 2025: Serverless GPUs, Autoscaling, Scale to Zero, and More!
We’re on a mission to simplify application deployment for developers and businesses worldwide, whether they're AI-driven models, full stack applications, APIs, or databases. Our next-generation serverless platform significantly accelerates your deployments and improves efficiency, enabling you to build more with less spend.
2024 was a major year for us, packed with crucial serverless milestones. From Autoscaling and scale to zero, to serverless GPUs and faster deployments, we've redefined the serverless deployment experience.
While we shared these updates in our weekly changelog updates, during two incredible launch weeks, and in our major announcements, we want to dive into the highlights here and discuss why 2025 is set to be even bigger. Here’s a quick rundown of the highlights:
- Serverless GPUs: Introduced a range of high-performance GPUs to the serverless compute line-up
- Autoscaling: Seamless scaling for GPU and CPU workloads
- Scale to zero: Optimize costs and performance for idle GPU and CPU workloads
- Faster Deployments: 70% faster high-performance networking
- Deploy Globally in 10+ Regions: Expanded global availability with Singapore, Paris, Tokyo GAs
- Volumes and Snapshots: High-performance storage and point-in-time copy of your data
- Larger database instances: For the most data-intensive applications
- New dashboard: A refreshed dashboard for the best UX
- One-Click Deployment Catalog: AI models, starter apps, observability, and more — all ready to go in seconds.
- Koyeb Startup Program: We’re supporting innovation for early-stage teams
- Pro and Scale Plans: Tailored plans for professional and growing teams
- New mascot: The Koyeb Croissant joins the party 🥐
- Koyeb Wrapped: Get your 2024 stats for Koyeb. Discover how many services you deployed, how many requests your services handled, and so much more!
Arrival of Serverless GPUs
We introduced serverless GPUs designed to support your AI inference workloads, AI agents, LLMs, computer vision models, fine-tuning, and small-scale training.
From 20GB to 80GB of vRAM, we provide different price points for all your training, fine-tuning, and inference needs. The H100s allow you to run high-precision calculations with FP64 instructions support and 2TB/s of bandwidth.
Just like all our other Instances, GPUs can autoscale based on different criteria including requests per second, concurrent connections, P95 response time, and CPU & memory usage. This provides a fast, flexible, and cost-effective way to optimize your GPU usage.
On top of bringing the serverless experience to GPUs, we slashed prices across our fleet of GPUs: L4, L40S, and A100 serverless GPUs. Combine scale to zero, autoscaling, and lower prices for huge improvements in efficiency - get more compute for less. Here’s a reminder of the price update:
- L4: $1.00 → $0.70/hour
- L40S: $2 → $1.55/hour
- A100: $2.70 → $2/hour
Whether you’re running inference, training models, or fine-tuning, Serverless GPUs let you scale AI projects without the complexity of managing infrastructure. If you want to run inference with larger models, we offer multiple A100 options, which also benefit from the price drop.
Run larger models, prototype more, and enjoy better performance without fear of costs. As always, we bill per second, so you only pay for what you use.
Autoscaling
Autoscaling hit GA! In short, autoscale fast, sleep well, and don’t break the bank. You can automatically scale your applications based on:
- Concurrent Connections
- P95 Response Time
- CPU Usage
- Memory Usage
- Requests per second
Every 15 seconds, we perform checks on your deployment to decide if it needs to scale. If you want to read more about how autoscaling works on the platform, check out our autoscaling engineering blog post.
Autoscaling is available on our GPU and Standard Instances. Managing unpredictable spikes and varying workloads is critical for your infrastructure. We believe autoscaling should be standard for any deployment: you deserve optimized resource utilization.
Scale to zero
A pivotal milestone, scale to zero is available in public preview for GPU and Standard CPU Instances. Combine it with autoscaling to enjoy the full serverless experience: Automatically sleep and wake up depending on incoming requests, and scale out horizontally based on your custom scaling criteria.
We’ve worked with our customers and partners to enable key use cases:
- Inference efficiency
- Dedicated Services for multi-tenant SaaS and platforms
- Infinite development environments
- Compute efficiency
- Global deployments
Now the critical question: cold starts. When we receive a new request, it takes from 1 to 5 seconds to create a new dedicated virtual machine. Scale-to-zero works across CPUs and GPUs, it's hardware agnostic. We call this scale-to-zero deep sleep.
We will bring cold starts down to a few hundred milliseconds very soon with memory snapshotting.
70% faster deployments
We released an optimized networking stack, which means your workloads enjoy 70% faster deployments.
When you deploy on the platform, you get advanced capabilities out-of-the-box, including: Automatic load-balancing, fully encrypted private networking, built-in observability, auto-healing, and automatic service discovery just to name a few.
All these features are tied to the networking stack. When building the platform, we needed the right tools to scale our platform in its early days. For our network stack, our goals included:
- Multi-tenancy
- Service discovery
- Observability
- Built-in load-balancing
- Resiliency
- Zero Trust Network
We chose Kuma, an open-source service mesh built on Envoy. Kuma took us from nothing to scaling 10s of thousands of apps running on Koyeb. Then, we started to hit limitations as we scaled. The green line shows the propagation time w/ Kuma vs our new network stack in yellow.
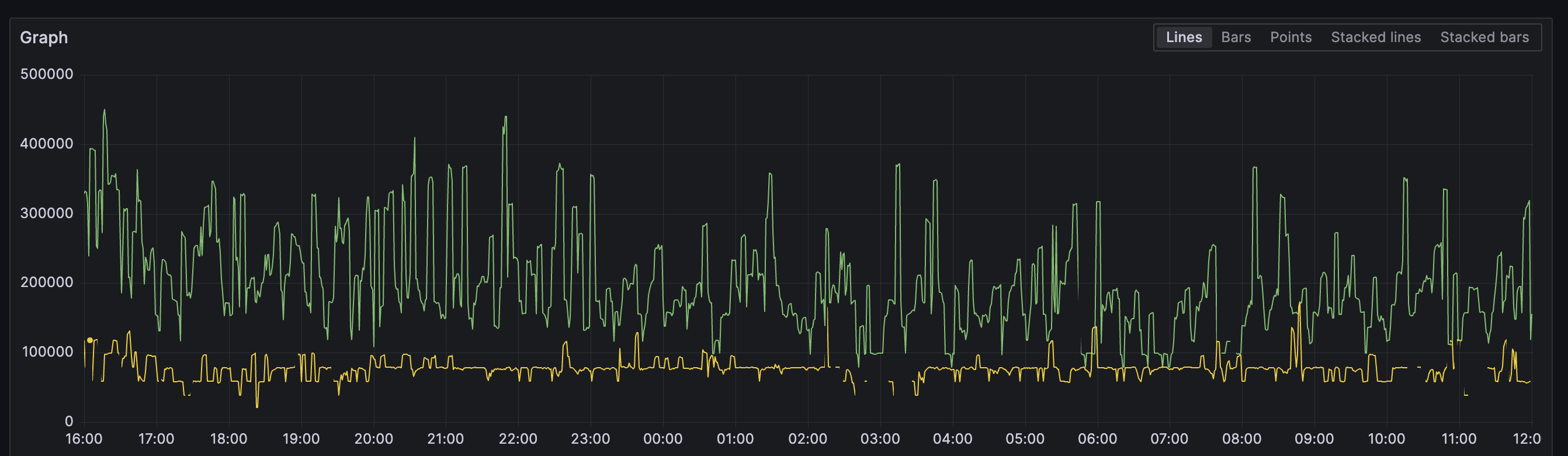
To ensure we can continue delivering the best possible experience, we decided to rethink our approach. Tl;dr - we decided to drop Kuma and Envoy for networking and opted for a custom-built stack on top of Envoy, Cilium, eBPF, and WireGuard VPN.
Over 10 regions to deploy applications worldwide
Singapore, Paris, and Tokyo are now generally available. GA locations now include Paris, Tokyo, Washington, D.C., Singapore, and Frankfurt. Deploy APIs, inference, full-stack apps, and databases everywhere! Everything you need is now available in our core locations:
- Standard Instances with blazing-fast CPUs for prod
- Workers for async processing
- Continuous deployment
- Autoscaling
- Built-in edge network
- Private network and service discovery
- Real-time logs and metrics
In addition to these core locations running on bare metal servers, we released AWS regions on to the platform! If you’re interested in running your workloads in AWS regions with the Koyeb deployment experience, book a call.
New regions also went live as we released new GPUs on the platform. You can run workloads on high-performance GPUs in the US and Europe. More on that next…
Volumes and Snapshots
When you deploy your apps on Koyeb, your data is on ephemeral disks. While this works great for stateless applications, this is challenging for stateful workloads like databases. This is why we released Volumes for high IOPS and low latency NVMe SSDs!
Volumes open the door to a wide range of new workloads and use cases to handle the state of your applications:
- Clustered databases
- Object storage
- Queue systems
- Storing model checkpoints and weights for AI workloads
Or anything else that requires data persistence. With Volumes, you can now deploy any stateful database like PostgreSQL, MySQL, Redis, Meilisearch, Weaviate, Turso, Minio, ClickHouse, MongoDB, Milvus, and Neo4j.
We also released Snapshots, which enable you to create a point-in-time copy of your high-performance volumes. Ideal for live backups, volume clones, data movement, and disaster recovery.
Larger managed PostgreSQL databases
We support managed Postgres databases, and last year larger managed Postgres instances with up to 4GB of RAM became available for workloads worldwide in Frankfurt, Singapore, and Washington, D.C.
Using Koyeb Serverless Postgres, you can easily start a resilient Database Service alongside your apps in a few seconds. You can build, run, and scale your full stack apps and manage their databases on a single platform with a unified experience.
Serverless Postgres Pricing allows up to 88% savings compared to traditional databases thanks to their high availability design and scale-to-zero capabilities.
New dashboard: Build, run, and scale apps in minutes
We modernized our control panel to transform your deployment experience. Under the hood of the control panel is high-performance infrastructure, advanced networking, and a range of powerful features to power your deployments.
We completely revamped the deployment experience. In just a few clicks, you can:
- Select your deployment method - via git or container registry
- Pick your Instance type among our range of GPUs and CPUs
- Choose where in the world you want to deploy
Next up, you’ll see a summary overview of your deployment. From there, you can configure env variables, autoscaling policies, and get an estimated cost for your deployment.
We also enhanced the build and deployments logs experience to give you even clearer insights into your deployment's progress. As soon as your deployment is healthy, you can access it using the public URL.
AI Models in the one-click deployment catalog
We introduced AI models in the one-click deployment catalog. With just a single click, you can deploy a dedicated endpoint for inference requests on high-performance infrastructure that automatically scales with your traffic.
These models are perfect for developers and teams looking for high-performance, autoscaling infrastructure without the complexity of manual setup. To kick things off, we've introduced six state-of-the art LLMs that you can deploy with just 1 click:
- Gemma 2 9B by DeepMind
- Hermes 3 Llama 3.1B by NousResearch
- Llama 3.1B by Meta
- Mistral 7B
- Phi 4 by Microsoft
- Qwen 2.5 7B
- SmolLM2 1.7B Instruct
On top of these initial LLMs, we’ll be releasing one-click deploy models for text-to-image generation, image editing, and more.
Pair one-click models with scale-to-zero and autoscaling for smarter resource use, instant readiness whenever new requests come in, and optimal performance
Koyeb Startup Program
We aim to support emerging startups that need best-in-class infrastructure to run and scale their businesses. That’s why we launched the Koyeb Startup Program. Eligible startups can apply to the program, claim up to $30k in Koyeb credits for Standard and GPU services and more perks.
Startups around the world lose precious time dealing with complex infrastructure. Time-to-market is critical and we're here to help you deploy and iterate quickly.
Go to market faster with high-performance cloud infrastructure and the best developer experience. Here's what you get when you join:
- Up to $30k of free compute credits that you can use with our Standard and GPU Instances
- Seamless onboarding
- Access to extra features, resources, and regions
- Priority support
- Early access to new features
See if you qualify for the Koyeb Startup Program and apply today.
Pro and Scale Plans
Manage fleets of high-performance apps as a team with our new Pro and Scale Plans! The Pro and Scale plans supersede the Startup plan with more users, more services, and included compute.
Here is a rundown of our 2025 plans:
- Starter: For individuals, a pay-per-use plan w/ a generous free tier
- Pro: Teams running production apps
- Scale: Scaling companies managing large deployments
- Enterprise: Mission-critical deployments, dedicated locations & compliance
All our plans include the ability to run inference workloads, APIs, Web Apps, Workers, and Databases with CPU and GPU access, scale to zero and autoscaling for Standard CPU and GPU Instances, and global deployments across US, EU, and Asia regions.
The philosophy stays the same with a flat fee, starting at $29 per month, and usage charged per second on top of it. Our 2025 plans are designed to increase clarity and provide a seamless evolution for all developers, startups, and businesses relying on the platform.
Get Your Personal Koyeb 2024 Recap
Wonder how many times you deployed last year? Want to know how many requests your Services handled? Check out your Koyeb Wrapped and find out all that and more: your top regions, how many services you created, and your deployment style.

Onward to 2025!
Last year was an extraordinary year. We released so many pivotal serverless features like scale to zero, autoscaling, high-performance serverless GPUs, and everything we recapped above. We’re so excited for everything that’s in store for 2025, including:
- Light sleep for even faster scale to zero experiences
- New accelerators and GPUs
- More advanced networking features
- Additional features for Volumes and Snapshots
Want to stay in the loop? Follow us on X @gokoyeb, read the weekly changelogs we share in the Koyeb community and on our blog, and keep an eye on our public roadmap. Want to see another feature on the platform? Tell us and vote for all the features you want to see with our feature request platform